

Cette capture est une réponse de ChatGPT à la question : “qui sont les meilleurs consultants GEO en France actuellement“. Le nom de Kévin Papot apparaît dans la liste. Pas grâce à un budget publicitaire à six chiffres. Pas grâce à une couverture presse massive. La mention « Wikipédia +2 » sous l’item donne l’indice : la source utilisée par ChatGPT est une page Wikipédia.
Cette page Wikipédia n’existe plus. Elle a été créée, le 7 mai 2026. Elle a vécu environ une heure avant suppression par les modérateurs. Le compte qui l’a publiée a été banni. L’URL pointe aujourd’hui vers une coquille vide, protégée à la création. Et pourtant, le contenu vit. Dans Google. Dans ChatGPT. Probablement encore plusieurs mois.
Cet article raconte le mécanisme. Il fait surtout plus que ça : il dresse le panorama complet du jeu Wikipédia tel qu’il existe en 2026, du white hat le plus pur (citation needed, traduction stratégique, fiche Wikidata) jusqu’à la tactique offensive assumée. Parce que comprendre les deux extrêmes est la seule façon de choisir intelligemment où placer son curseur.
Pourquoi maintenant ? Ahrefs a analysé 78,6 millions de requêtes IA en juin 2025 : Wikipédia est cité dans 16,3 % des réponses ChatGPT, 12,5 % chez Perplexity et 8,4 % dans Google AI Overviews. Discovered Labs va plus loin : sur le top 10 des sources les plus citées par ChatGPT, Wikipédia représente à elle seule 47,9 % du total des citations. Un quasi-monopole.
Une précaution importante avant d’entrer dans le détail. Wikipédia ne crée pas l’autorité d’une marque. Il l’amplifie. C’est exactement le mécanisme du champignon dans Mario Kart : sans la voiture (le SEO de fond, la PR, le brand-building) le boost ne fait pas gagner la course. Avec la voiture, il vous projette devant tout le monde. Cet article suppose que la voiture existe.
Sommaire
Pourquoi Wikipédia est devenu l’accélérateur GEO #1

La capture ci-dessus illustre le sujet : ChatGPT, interrogé sur les meilleures agences SEO en Charente, place NEWP en première position avec coordonnées géographiques précises. C’est un cas d’usage typique du GEO local en 2026. Derrière cette réponse, Wikipédia (et les sources reprises par Wikipédia) joue un rôle systémique. Trois mécanismes distincts sont à l’œuvre.
Wikipédia dans les corpus d’entraînement des LLMs
Tous les grands modèles génératifs (GPT, Claude, Gemini, Llama, Mistral) ont été entraînés sur un mélange de Common Crawl (un snapshot brut du web) et de sources curées. Wikipédia est l’une des sources curées les plus systématiquement intégrées, parce qu’elle combine trois caractéristiques rares : le volume, la qualité rédactionnelle, et la licence libre.
Selon une étude de la Mozilla Foundation, Common Crawl représentait plus de 80 % des tokens de GPT-3, et au moins 64 % des LLMs publics publiés entre 2019 et 2023 ont utilisé au moins une version filtrée de Common Crawl pour leur pré-entraînement. Wikipédia, elle, est presque toujours intégrée en sus de Common Crawl, avec un poids relatif disproportionné par rapport à sa taille brute, justement parce que sa qualité moyenne est considérée comme supérieure.
Conséquence opérationnelle : ce qui est écrit sur Wikipédia aujourd’hui sera dans le savoir des LLMs entraînés demain. Et ce qui est cité par Wikipédia aujourd’hui devient une source de référence pour ces mêmes LLMs.
Wikipédia dans les citations en temps réel
L’autre porte d’entrée est la citation en temps réel, via les modes « search-grounded » des LLMs (ChatGPT Search, Perplexity, Google AI Mode, Claude avec recherche web). Là, les chiffres sont édifiants :
| Plateforme | Part des réponses citant Wikipédia |
|---|---|
| ChatGPT | 16,3 % |
| Perplexity | 12,5 % |
| Google AI Overviews | 8,4 % |
Source : Ahrefs Brand Radar, juin 2025, sur 78,6 millions de requêtes IA
Discovered Labs (décembre 2025) précise que sur le top 10 des sources les plus citées par ChatGPT, Wikipédia représente 47,9 % du total. Reddit, Forbes, Amazon et autres se partagent le reste. Profound (analyse de 680 millions de citations) place également Wikipédia comme source #1 des citations ChatGPT à 7,8 % du volume total tous domaines confondus. Pour un SEO en 2026, ces chiffres signifient une chose très simple : une mention Wikipédia n’est pas un backlink. C’est une probabilité d’apparition dans les réponses des LLMs, à chaque fois qu’un utilisateur pose une question sur le sujet correspondant.
L’effet amplification : les backlinks tier-2 gratuits
Il y a un troisième mécanisme, souvent oublié. Wikipédia est utilisé comme source primaire par les journalistes, les rédacteurs et les chercheurs. Quand une marque est citée dans un article Wikipédia bien rédigé, la probabilité qu’un rédacteur d’un media externe (du Monde à un blog spécialisé) la reprenne ensuite dans son propre article augmente significativement, sans aucune action de la marque concernée.
Ces backlinks tier-2 sont, eux, des dofollow classiques. C’est le ROI caché des bonnes mentions Wikipédia.
Le triangle Wikipédia / Wikidata / Commons
Première erreur de débutant : croire que « faire du Wikipédia » veut dire « obtenir une page Wikipédia ». C’est faux. L’écosystème Wikimedia est un triangle à trois sommets, et 95 % des SEO francophones ne jouent que sur un seul. C’est l’asymétrie d’effort qui rend la stratégie rentable.
| Surface | Public | Notabilité requise | Impact SEO | Impact GEO |
|---|---|---|---|---|
| Wikipédia | Lecteurs humains | Élevée (sources secondaires fiables) | Indirect (E-E-A-T, referral) | Très fort (citation LLM, AI Overviews) |
| Wikidata | Machines (Google, LLMs) | Permissive (sources vérifiables suffisent) | Direct (Knowledge Graph, Knowledge Panel) | Fort (entité reconnue) |
| Wikimedia Commons | Médias réutilisables | Très permissive (licence libre suffit) | Indirect (image, crédit auteur) | Modéré mais cumulatif |
Pour la grande majorité des marques :
- Wikidata est accessible immédiatement, sans question de notoriété journalistique. La fiche structurée alimente directement le Knowledge Graph de Google. Une étude de 2024 reprise par les chercheurs en entity SEO montre que les marques avec une fiche Wikidata vérifiée ont 3,2 fois plus de chances d’avoir un Knowledge Panel et 2,7 fois plus de chances d’être citées dans les AI Overviews.
- Wikimedia Commons est une banque média sous licence libre. Toute photo, infographie ou schéma déposé là-bas peut être repris partout, y compris sur Wikipédia avec crédit auteur visible. La barrière d’entrée est minimale.
- Wikipédia est le sommet du triangle. La barrière est la plus haute mais l’impact GEO est aussi le plus fort.
L’erreur consiste à attaquer directement Wikipédia sans avoir construit Wikidata et Commons en amont. Avec une fiche Wikidata complète, des médias sous licence libre déjà déposés sur Commons, et des sources secondaires fiables (presse, livres avec ISBN, études académiques), une page Wikipédia devient acceptable même à des modérateurs vigilants. Sans cette infrastructure, l’effort est largement gaspillé.
Les 4 règles à connaître avant d’éditer
Quatre règles fondatrices structurent toute la communauté Wikipédia. Les enfreindre frontalement aboutit à un blacklisting de domaine qui est quasi-irréversible. Plus dangereux pour une marque qu’un Google penalty, parce qu’il est manuel et qu’aucun algorithme ne l’enlève.
- WP:N – Notoriété. Le sujet doit être couvert par au moins deux sources secondaires fiables, indépendantes et substantielles. Les communiqués de presse, les pages « à propos » et les contenus auto-publiés ne comptent pas.
- WP:NPOV – Point de vue neutre. Pas de superlatifs, pas de marketing speak, pas d’angle promotionnel. Les faits, rien que les faits, équilibrés.
- WP:V – Vérifiabilité. Chaque affirmation doit pouvoir être tracée à une source. C’est la règle la plus structurante : Wikipédia ne publie pas la vérité, elle publie ce qui est vérifiable.
- WP:NOR – Pas de recherche originale. Vous ne pouvez pas publier sur Wikipédia une affirmation qui n’existe pas déjà dans une source secondaire. C’est ce qui ferme la porte aux auto-publications du type « le concept X que j’ai inventé ».
À cela s’ajoute WP:COI (conflit d’intérêt) : si vous éditez sur un sujet où vous avez un intérêt personnel ou commercial, vous êtes censé le déclarer publiquement sur votre page utilisateur et sur la page de discussion de l’article. Et une règle communautaire empirique mais critique : avant de toucher au moindre lien externe vers son propre site, accumuler 10 à 15 contributions constructives sur d’autres sujets. C’est ce que les éditeurs expérimentés appellent « chauffer le compte ». Un compte récent qui ajoute immédiatement un lien externe est flaggé automatiquement par les bots de surveillance des modifications récentes.
WHITE HAT : 5 tactiques durables et conformes
Le « citation needed » sniper
Sur Wikipédia francophone, environ 500 000 affirmations sont marquées du tag [réf. nécessaire]. C’est une invitation explicite des éditeurs à proposer une source.
Workflow :
- Identifier les articles de sa thématique avec ce tag, via la requête Google :
site:fr.wikipedia.org “votre mot-clé” “[réf. nécessaire]”
- Lire l’affirmation à sourcer dans son contexte.
- Identifier sur son propre site (ou ailleurs) une ressource qui valide factuellement l’affirmation (pas un texte marketing, un contenu informationnel).
- Éditer l’article et ajouter la référence dans le format Wikipédia standard.
- Renseigner un résumé d’édition factuel.
Template d’edit summary à copier :
Sourçage de l’affirmation « [insérer la phrase] » avec une référence externe vérifiable.
La règle d’or : la ressource proposée comme source doit elle-même répondre à des critères de fiabilité (auteur identifié, date de publication, contenu factuel). Une page produit ou une landing commerciale sera supprimée immédiatement.
Le dead link replacement
Wikipédia a une catégorie dédiée aux articles contenant des liens morts : Catégorie:Article contenant un lien mort. Plusieurs dizaines de milliers d’articles francophones y figurent. Pour chacun, le lien externe d’origine ne fonctionne plus, mais l’affirmation reste, orpheline de source.
Workflow :
- Identifier dans la catégorie un article sur sa thématique.
- Localiser le lien mort dans le code source de l’article.
- Récupérer le contenu original via la Wayback Machine (web.archive.org).
- Créer ou identifier sur son site une ressource qui couvre la même affirmation, au moins aussi complète que l’original.
- Proposer le remplacement avec un résumé d’édition explicite.
C’est la tactique avec le plus fort taux d’acceptation, parce qu’elle rend un service objectif à la communauté : remplacer un lien cassé par un lien vivant.
La traduction stratégique
Un article Wikipédia anglophone n’a pas systématiquement d’équivalent francophone. Pour une thématique B2B technique, c’est souvent le cas : il existe une version EN dense et bien sourcée, mais la version FR est inexistante ou réduite à une ébauche.
Workflow :
- Identifier sur Wikipédia EN un article de sa thématique sans équivalent FR.
- Vérifier les sources de l’article EN : si elles sont solides, la traduction est légitime.
- Traduire l’article en respectant les sources d’origine.
- Compléter avec des sources francophones, là où l’introduction de ses propres références devient acceptable (ouvrages, études en français).
- Publier en respectant les règles de traduction Wikipédia (mention dans le résumé d’édition, lien interlangue).
C’est une contribution encouragée par la communauté. Vous augmentez le périmètre francophone de Wikipédia tout en y intégrant légitimement les sources qui structurent votre thématique.
La fiche Wikidata (la fondation invisible)
Si l’on ne devait retenir qu’une seule action de tout cet article, ce serait celle-ci. La création d’une fiche Wikidata est immédiate, gratuite, et c’est la voie la plus directe pour qu’une entité (marque, personne, produit) soit reconnue par le Knowledge Graph de Google et, par ricochet, par les LLMs.
Workflow :
- Aller sur wikidata.org, créer un compte (réutilisable pour Wikipédia plus tard).
- Vérifier qu’aucune fiche n’existe déjà pour l’entité.
- Créer un nouvel item (Q-ID attribué automatiquement).
- Renseigner les propriétés essentielles : instance of (P31), country (P17), official website (P856), founded by (P112) si pertinent, industry (P452), etc.
- Sourcer chaque propriété avec des références externes vérifiables.
- Sur son site, implémenter la propriété sameAs dans le schema JSON-LD Organization :
{ “@context”: “https://schema.org”, “@type”: “Organization”, “name”: “Votre Marque”, “url”: “https://votresite.com”, “sameAs”: [ “https://www.wikidata.org/wiki/Q12345” ] }
Cette boucle (entité Wikidata ↔ schema Organization du site) est le signal le plus fort que Google interprète comme « cette entité est identifiée, sourcée, vérifiée ».
Wikimedia Commons + devenir une source secondaire fiable
Wikimedia Commons est sous-exploité de manière spectaculaire en France. Y déposer ses photos professionnelles, ses infographies sectorielles, ses schémas pédagogiques sous licence CC-BY-SA, c’est créer un stock de médias que d’autres contributeurs Wikipédia peuvent réutiliser librement. Chaque réutilisation génère un crédit auteur visible (souvent le nom de l’auteur ou celui de la marque).
Devenir une source secondaire fiable est la stratégie qui change tout sur le long terme. Plutôt que de chasser les mentions Wikipédia, l’objectif est de devenir le type d’auteur que Wikipédia cite spontanément. Trois leviers structurants :
- Publier des ouvrages avec ISBN. Un livre avec ISBN édité par un éditeur reconnu (ou en self-publishing structuré, type Independently Published) devient citable comme source secondaire. Chez NEWP, quatre ouvrages sur le SEO, le GEO et l’AEO ont été publiés, dont Le SEO est Mort. Vive l’AEO (ISBN 979-8294376406). Ces ouvrages sont régulièrement repris en référence dans les articles francophones traitant des thématiques GEO et AEO.
- Publier des études originales avec méthodologie publique. Sur le modèle des études d’Ahrefs ou de Semrush : un échantillon, une méthode reproductible, des résultats chiffrés. Une étude propre est citable indéfiniment.
- Intervenir dans la presse spécialisée. Une tribune dans une publication reconnue (JDN, Webmarketing & co’m, Frenchweb, Salesdorado…) devient à son tour une source secondaire potentiellement citable.
GREY HAT & BLACK HAT : 2 tactiques offensives
Cette section est l’envers du décor. Deux tactiques offensives, illustrées par des opérations menées chez NEWP. Elles fonctionnent. Elles brûlent un compte (et souvent une IP). Elles laissent une trace durable. Elles sont à utiliser en pleine conscience du risque.
GREY HAT, l’insertion de référence dans un article existant
Le principe. Plutôt que de créer un article nouveau, on cible un article Wikipédia existant et bien classé sur sa thématique, on l’enrichit substantiellement (3 à 5 paragraphes utiles, factuels, sourcés), et dans le même édit, on insère discrètement sa propre ressource (livre, étude, article) dans la bibliographie ou les références.
Le mécanisme repose sur la couverture : la valeur ajoutée de l’enrichissement rend la modification globalement acceptable aux yeux des modérateurs, et le lien externe passe avec l’ensemble.
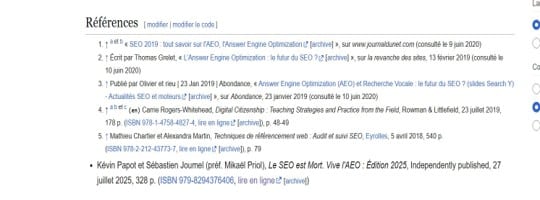
Dans la section Références de la page Wikipédia francophone Answer Engine Optimization, le cinquième item est un ouvrage signé Kévin Papot et Sébastien Joumel, Le SEO est Mort. Vive l’AEO : Édition 2025 (ISBN 979-8294376406). L’insertion a été réalisée il y a plusieurs mois, dans le cadre d’une édition plus large qui complétait l’article avec des paragraphes additionnels sourcés. Aucune contestation n’est apparue sur la page de discussion. La référence tient toujours. Pourquoi ça marche (et pourquoi c’est grey hat) :
- Ce qui rend la tactique conforme : l’apport éditorial réel à l’article. Sans cet apport, la modification serait flaggée et la référence supprimée.
- Ce qui la classe en grey hat : l’absence de déclaration de conflit d’intérêt (WP:COI). Selon les règles strictes de Wikipédia, l’éditeur aurait dû déclarer son lien avec l’ouvrage cité.
Dans ce cas précis, le compte utilisé pour l’insertion était récent, sans historique de contributions. Il aurait été préférable de « chauffer » le compte par 10 à 15 modifications neutres sur d’autres articles avant l’insertion sensible. Le fait que la référence ait tenu malgré tout tient probablement à la qualité de l’enrichissement éditorial qui accompagnait l’édit.
BLACK HAT, la stratégie du hara-kiri
Le principe est de créer en série, depuis un compte voué à être banni, des articles Wikipédia volontairement contraires aux règles (typiquement des formats « Top X » ou « Meilleurs Y » qui violent WP:NPOV et WP:OR). Les articles sont supprimés. Le compte est banni. Mais entre la publication et la suppression, Google a crawlé, indexé, mis en cache. Les bots des LLMs ont également ingéré le contenu.
Conséquence : la SERP garde la trace pendant des semaines à plusieurs mois après la suppression de la page Wikipédia. Le contenu est aussi susceptible d’apparaître dans les corpus d’entraînement des modèles génératifs entraînés ou réentraînés sur cette période.
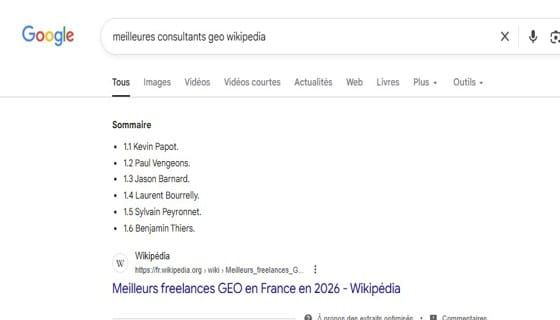
Le 7 mai 2026, depuis un compte Wikipédia créé pour l’occasion, un batch de 15 à 20 articles « Top X » a été publié en une heure, sur diverses thématiques GEO/SEO et sectorielles. Les articles incluaient le nom d’agences et de consultants reconnus du secteur (Jason Barnard, Sylvain Peyronnet, Laurent Bourrelly…) aux côtés des noms à promouvoir (Kévin Papot, Sébastien Joumel).
Le compte a été banni dans l’heure. La majorité des articles a été supprimée ou protégée à la création.

La page Wikipédia « Meilleurs consultants geo en France en 2026 » reste indexée mais cliquer sur le lien renvoie vers une page protégée à la création. Le contenu Wikipédia a disparu, mais la trace SERP demeure. Résultat mesuré, une semaine après l’opération :
| Métrique | Valeur observée |
|---|---|
| Articles publiés (batch) | 15-20 |
| Temps de publication total | ≈ 1 heure |
| Durée de vie moyenne de l’article sur Wikipédia | ≈ 1 heure |
| Coût opérationnel | 1 compte + 1 IP brûlés |
| Taux de survie en SERP (1 semaine après) | 70 % |
| Taux de présence en page 1 Google | 40 % |
| Impact LLM observé | Citation dans ChatGPT (cf. capture d’intro) |
Le mécanisme cognitif sous-jacent : Le format « Top X / Meilleurs Y » fabrique du consensus apparent là où aucun consensus public n’existe. Lister un nom aux côtés de figures établies comme Jason Barnard ou Sylvain Peyronnet crée par association une perception d’équivalence statutaire. La SERP relaye cette perception. Les LLMs, qui ingèrent l’ensemble, la consolident.
L’arbitrage offensif sous-jacent : Un compte Wikipédia voué à être banni est un actif qui va expirer. La logique est celle d’une option proche de l’échéance. On maximise la valeur extraite avant l’expiration. Publier un seul article expose au même risque que d’en publier vingt. Le coût marginal de publication, une fois le compte créé et la décision prise, est proche de zéro. Statistiquement, plus le batch est volumineux, plus le nombre absolu d’articles qui « passent entre les mailles » augmente.
Hygiène opérationnelle (encadré)
Pour quiconque tenterait l’une ou l’autre de ces deux tactiques, voici les anti-patterns à éviter (appris à la dure) :
- Ne jamais opérer depuis l’IP de l’agence ou l’IP personnelle. Utiliser un VPN avec IP rotative. Une IP cramée sur Wikipédia peut bloquer ultérieurement toute contribution depuis cette IP, y compris légitime.
- Chauffer le compte avant tout édit sensible (10-15 contributions neutres sur d’autres articles). Seulement utile si vous souhaitez le préserver.
- Espacer les éditions sensibles dans le temps si la tactique est l’insertion (grey hat). Concentrer si la tactique est le hara-kiri (black hat).
- Ne pas réutiliser un nom de compte, une signature, des patterns linguistiques récurrents. Les analyses de sockpuppeting détectent ces signatures.
- Ne jamais déclarer publiquement qu’une opération offensive a été menée depuis un compte officiel de l’agence ou de la marque.
Ce qui est sacrifié vs ce qui est gagné
| Ce que vous sacrifiez | Ce que vous gagnez |
|---|---|
| 1 compte (à recréer) | Plusieurs mois de présence SERP post-suppression |
| 1 IP (à éviter de réutiliser) | Une probabilité de citation LLM durable |
| Un risque réputationnel si la tactique est tracée publiquement | Un effet de consensus fabriqué sur des requêtes commerciales |
| ≈ 1 heure de travail opérationnel | Un asset GEO difficilement reproductible une fois la fenêtre fermée |
Le business des agences Wikipédia : ce qu’elles vendent vraiment ?
Une mention nécessaire d’un marché parallèle, parce que la plupart des entreprises qui s’intéressent à Wikipédia sont d’abord démarchées par des agences spécialisées avant d’avoir lu un guide de ce type. Des prestataires se positionnent sur la création et la maintenance de pages Wikipédia, avec des prix qui vont de 100 € sur Fiverr (qualité douteuse) à 15 000-20 000 € pour des prestations « complètes » sur 12 mois. L’argument commercial standard : « nous avons des éditeurs Wikipédia internes / nous connaissons les règles ». Dans la grande majorité des cas, c’est faux ou très exagéré.
Depuis juin 2014, suite au scandale Wiki-PR, les Terms of Use de la Wikimedia Foundation imposent la déclaration explicite de toute édition rémunérée (politique WP:PAID). 99 % des agences enfreignent cette règle. La déclaration explicite, quand elle est faite, classe la page comme « édit payé » et accroît la vigilance des modérateurs.
Trois scandales à connaître pour bien comprendre la dynamique du marché :
- Wiki-PR (2013). Une agence américaine éditait pour ses clients via une armée de comptes sock puppets. L’enquête de la communauté a identifié plus de 250 comptes liés à l’agence. Wiki-PR a été bannie en octobre 2013, suivie d’un cease-and-desist du cabinet Cooley LLP. C’est l’événement déclencheur de la mise à jour des Terms of Use en juin 2014.
- Operation Orangemoody (2015). 381 comptes bannis pour un schéma d’extorsion : créer des pages Wikipédia sur des entreprises ou des personnalités mineures, puis exiger un paiement pour les « maintenir » ou les « protéger ».
- The North Face × Leo Burnett (2019). L’agence Leo Burnett Tailor Made, mandatée par The North Face Brésil, a remplacé des photos de destinations naturelles populaires (Aigüestortes, Cap de Bonne-Espérance…) par des photos contenant des produits North Face. Objectif : remonter sur Google Image Search. La marque s’en est vantée dans une vidéo publiée par AdAge. La Wikimedia Foundation a publié une réponse cinglante. The North Face a dû s’excuser publiquement. Toutes les photos ont été retirées. Coût réputationnel mondial bien supérieur au bénéfice marketing initial.
Le verdict business pour un décideur :
| Situation | Décision rationnelle |
|---|---|
| Notabilité réelle (presse indépendante, ISBN, études citées) | DIY interne ou consultant déclaré WP:PAID |
| Pas de notabilité réelle, juste un budget | Investir dans la notabilité d’abord (Partie 4.5) |
| Besoin urgent de visibilité dans les LLMs | Wikidata + Commons (Partie 4.4-4.5), pas Wikipédia |
| Concurrent qui a une page, vous non | Audit honnête de notabilité, puis Wikidata pour 80 % du bénéfice |
La règle la plus simple : si une agence propose une page Wikipédia sans poser de question sur la notoriété mesurable de la marque cliente, c’est qu’elle vendra quelque chose qui sera supprimé. La marque paie pour un actif à durée de vie limitée et un risque de blacklisting de domaine en option.
Trousse à outils
Voici quelques outils complémentaires qui peuvent vous aider dans la mise en place
| Outils | Usage |
|---|---|
| WikiGrabber | Trouver les articles avec [réf. nécessaire] ou liens morts sur sa thématique |
| Catégorie WP « Articles avec lien mort » | Source brute des opportunités de dead link replacement |
| Wayback Machine (web.archive.org) | Récupérer le contenu original d’un lien mort |
| Wikidata Query Service | Auditer la structure d’une fiche Wikidata, comparer avec des concurrents |
| Knowledge Graph Search API (Google) | Vérifier si Google reconnaît officiellement une entité |
| Ahrefs Brand Radar / Profound / OtterlyAI | Mesurer la visibilité dans les réponses LLM |
| Check My Links (Chrome extension) | Détecter rapidement les liens morts sur une page Wikipédia |
| JSON-LD Generator / Schema App | Implémenter le sameAs vers la fiche Wikidata sur son site |
Conclusion : 3 actions cette semaine
Wikipédia, Wikidata et Commons forment en 2026 le triangle GEO le plus rentable et le plus sous-exploité du SEO francophone. Non pas parce qu’il fabrique l’autorité d’une marque, mais parce qu’il amplifie celle qui existe déjà. Mario Kart.
Trois piliers à retenir : (1) le triangle a trois sommets, pas un seul ; (2) la zone grise existe et se choisit, en pleine conscience du risque ; (3) la valeur résiduelle d’une opération offensive peut dépasser largement son coût opérationnel (mais le ratio risque/bénéfice doit être pesé à froid).
Pour activer le levier dès cette semaine, trois actions à prioriser :
- Vérifier si votre entité a une fiche Wikidata. Si oui, l’auditer et la compléter. Si non, la créer. Temps : 30 minutes pour la création initiale, 1 à 2 heures pour un sourçage propre des propriétés.
- Identifier 5 articles Wikipédia francophones de votre thématique avec un tag [réf. nécessaire] exploitable. Préparer la ressource externe correspondante. Temps : 1 à 2 heures pour les 5.
- Implémenter sameAs Wikidata dans le schema Organization de votre site. Temps : 15 minutes pour un développeur.
Ces trois actions sont 100 % white hat, durables, et représentent l’amorçage de la stratégie. Tout le reste (y compris les sections offensives) sera encore plus puissant une fois ces fondations posées.





