zAI, la startup pékinoise derrière la famille GLM, a sorti GLM 5.2 à la mi-juin. Le modèle est ouvert, sous licence MIT, et il se place juste derrière GPT-5.5 et Claude Opus 4.8 sur le banc d’essai d’Artificial Analysis. Le tout pour un prix dix fois plus bas. Si vous suivez vos budgets d’IA dans une équipe commerciale ou marketing francophone, ça vaut le coup de regarder de près : un modèle de ce niveau, qu’on peut télécharger et héberger chez soi, ça change pas mal de choses.
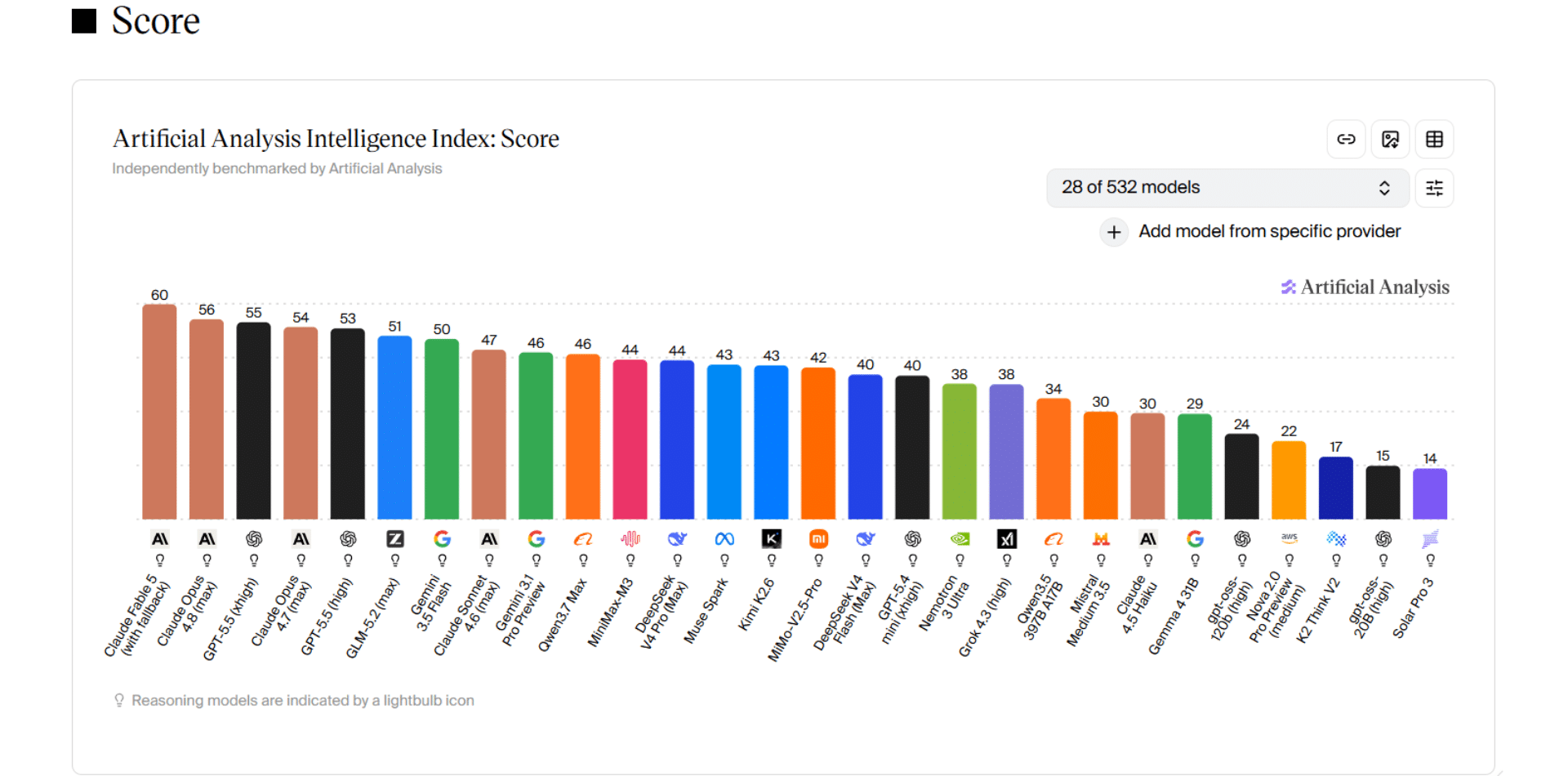
- GLM 5.2 obtient 51 points sur 100 sur l’Intelligence Index d’Artificial Analysis, le meilleur score jamais atteint par un modèle open weight, devant DeepSeek V4 Pro et Kimi K2.6.
- Il se loge juste derrière GPT-5.5 (55) et Claude Opus 4.8 (56), pour environ 1,4 dollar en entrée et 4,4 dollars en sortie par million de tokens.
- Architecture mixture of experts de 744 milliards de paramètres, fenêtre de contexte d’un million de tokens, licence MIT.
- Modèle téléchargeable et hébergeable sur site, un argument de souveraineté pour les organisations francophones.
- Son arrivée suit le blocage par Washington des modèles Fable 5 et Mythos 5 d’Anthropic.
- Le revers : la course à la consommation de tokens, le « tokenmaxxing », peut faire déraper les budgets.
Sommaire
Un modèle ouvert qui talonne les ténors américains
Sur l’Intelligence Index d’Artificial Analysis, GLM 5.2 décroche 51 points sur 100. Onze de plus que GLM 5.1, et surtout le meilleur résultat jamais signé par un modèle à poids ouverts. Il passe devant MiniMax M3 et DeepSeek V4 Pro (44 points chacun), devant Kimi K2.6 (43), et même devant Gemini 3.5 Flash (50). Au-dessus de lui, il ne reste que GPT-5.5 (55) et Claude Opus 4.8 (56). Pour donner une idée de l’écart, Fable 5 d’Anthropic plafonnait à 60 avant son retrait du marché.
zAI revendique aussi une deuxième place mondiale sur le banc front-end de Code Arena, derrière le seul Fable 5, d’après Yellow.com. Itamar Golan, patron de Prompt Security, résume bien le sentiment des testeurs : c’est le premier modèle ouvert qui ne décroche pas franchement face aux meilleurs systèmes propriétaires.
744 milliards de paramètres et un contexte d’un million de tokens
GLM 5.2 reprend l’architecture mixture of experts de la version d’avant : 744 milliards de paramètres au total, mais seulement 40 milliards qui s’activent à chaque requête. Du coup, la facture de calcul reste contenue, puisque le modèle ne mobilise jamais tout son poids pour une réponse.
Le vrai bond, c’est la fenêtre de contexte. Elle passe de 200 000 à un million de tokens. De quoi avaler d’un coup un appel d’offres complet, des mois d’historique CRM ou toute une base documentaire. zAI assure avoir entraîné le modèle sur de longs contextes réels, pas juste collé un chiffre sur la fiche produit. Une technique maison baptisée IndexShare fait tomber de 75 % le coût d’indexation lié à ces contextes étendus.
L’argument qui fait la différence : le prix
C’est là que ça devient intéressant pour les directions qui surveillent la dépense. zAI facture 1,4 dollar le million de tokens en entrée et 4,4 dollars en sortie. Anthropic, lui, demande 5 et 25 dollars pour Opus. On parle d’un écart de un à cinq, et même davantage côté sortie.
Wade Foster, le patron de Zapier, a fait tourner le modèle sur son propre banc d’essai, AutomationBench. Son verdict : GLM 5.2 égale le meilleur score d’Opus 4.7 max, pour 0,67 dollar par tâche contre 1,80 dollar. Moins de la moitié du prix.
| Modèle | Prix entrée ($ / million de tokens) | Prix sortie ($ / million de tokens) |
|---|---|---|
| GLM 5.2 (zAI) | 1,4 | 4,4 |
| Claude Opus 4.8 (Anthropic) | 5 | 25 |
Un bémol quand même : GLM 5.2 raisonne plus, donc il consomme plus de tokens. Artificial Analysis relève 43 000 tokens par tâche en moyenne, contre 26 000 pour la version 5.1. Le gain au token reste large, mais le volume monte, et c’est lui qu’il faut garder à l’œil.
Ce que GLM 5.2 change pour les équipes commerciales et marketing ?
Un modèle de ce niveau à ce prix, ça abaisse la barrière d’entrée sur tous les usages commerciaux du quotidien : enrichissement de fiches prospects, qualification de leads, rédaction de séquences de prospection, résumé d’appels, scoring d’opportunités. Toutes ces tâches répétitives qui tournaient sur un modèle premium peuvent passer sur GLM 5.2 sans faire grimper la note.
Le statut open weight ajoute l’argument que les responsables IT et les DSI du marché francophone attendaient : héberger le modèle sur site, en France, en Belgique, en Suisse ou au Luxembourg, plutôt que d’envoyer des données clients vers un cloud étranger. À garder en tête : passer par l’API chinoise expose à la loi chinoise sur le renseignement, qui peut imposer un accès aux données qui transitent. L’hébergement local écarte ce risque, mais il a un coût.
En FP8, le modèle pèse près de 900 Go et réclame au minimum huit GPU Nvidia H100. Comptez autour de 400 000 dollars à l’achat, ou 20 000 dollars par mois en location, d’après Itamar Golan. Des versions compressées par Unsloth tiennent sur une grosse station de travail, à condition d’accepter une perte de qualité.
Le contexte : le blocage de Fable 5 et Mythos 5
L’arrivée de GLM 5.2 ne doit rien au hasard. Le 12 juin, le département du Commerce américain a ordonné à Anthropic de couper l’accès étranger à ses modèles Fable 5 et Mythos 5 sous 48 heures, pour un motif de sécurité. Les deux modèles ont été désactivés partout dans le monde, pour tous les clients. zAI a publié son modèle ouvert le lendemain.
Le geste relance la course entre laboratoires chinois et américains. L’AI Index 2026 de Stanford chiffre l’écart entre les meilleurs systèmes des deux pays à 2,7 points de pourcentage, même si l’avance américaine reste plus nette sur les tâches de raisonnement les plus dures. Le fondateur de zAI, Tang Jie, a d’ailleurs contredit publiquement Elon Musk, qui voyait un rival chinois de Fable 5 arriver seulement début 2027.
Le revers de la médaille : attention au tokenmaxxing
Un modèle moins cher ne dispense pas de piloter ses coûts. Un phénomène monte dans les grands groupes : le « tokenmaxxing », qui consiste à juger les salariés sur leur consommation de tokens pour pousser l’adoption de l’IA. Amazon, JPMorgan, Meta et Disney auraient mis en place des classements internes de ce genre. Un salarié de Disney aurait interagi 460 000 fois avec Claude en neuf jours, rapporte Business Insider.
Le problème, bien résumé par Logan Wolfe de Kyndryl : la consommation de tokens ne dit rien de la productivité réelle. On récompense le volume, pas le résultat, et la facture grimpe pendant que la qualité stagne. Le conseil des spécialistes interrogés par CIO tient en une phrase : suivez des indicateurs de résultat, comme le code réellement déployé ou les affaires gagnées, plutôt que le nombre de tokens brûlés. Un modèle à 1,4 dollar le million ne vous protège de rien si chaque tâche en consomme dix fois trop.
Pour les équipes francophones, GLM 5.2 n’est pas qu’une curiosité venue de Pékin. C’est une vraie option pour les tâches courantes, à condition de cadrer les usages et de garder un modèle premium sous le coude pour les dossiers les plus costauds. Le bon réflexe : testez sur vos propres cas, chiffrez le coût par tâche, et tranchez sur pièces.