
Web scraping is the extraction of data from a website in a structured way. It is a useful method in many situations:
- Generate prospecting files,
- Enrich a dataset,
- Personalise the customer experience automatically, etc.
In this article, we will present 10 methods and tools for web scraping. From the eternal copy and paste (which works much better than you might think), to more complex methods for larger projects. 7 of these 10 methods require no (or almost no) prior knowledge.
Sommaire
/en/1. Copy and paste
It may sound silly, but we often forget how well copy and paste works. You can copy and paste all the tables that are on Wikipedia into an Excel file or a Google Spreadsheet, for example. If you are looking for postcodes, common first names, telephone codes, it takes a minute with this method. This job literally takes a minute, and I’ve found myself searching for a complicated pattern on a table or grid several times, when a copy and paste would do the trick. Automation is good, but it sometimes takes much longer than a method as simple and efficient as copy and paste.
- Extremely easy to use,
- Very quick to make.
- Very limited.
#2. CaptainData
LinkClump is one of the best Chrome extensions to boost your sales. Using it is a breeze! With LinkClump, you can :
- Retrieve links and their titles very easily,
- Select only the important links on a given page,
- Download image or file banks (in combination with TabSave).
If you look around, there are a lot of things that are actually just links to web pages for SEO reasons. For example, most directories put a link to a child page on all their titles. With LinkClump, you can get the URLs & titles of all these pages in no time. The most common use case is the google results page, but there are many others.
- Extremely easy to use,
- An easily accessible and very space-saving Chrome extension.
- You can download a large amount of data in no time.
- Quite limited
#4. TabSave: scrape a bank of images or files
Image or file banks are usually presented in the form of an image with a link to the source, again to be careful with SEO. So you can use LinkClump to get all the links from the sources. This is where TabSave comes in. Just paste all those links into TabSave, and click on “Download”. Powerful enough to retrieve large amounts of media files from the web.
Salesdorado’s advice
Go to chrome://settings/?search=downloads. Under Downloads > Location, specify a target folder created for the occasion. All files downloaded by your browser will now go into this folder. A good way to avoid cluttering your Downloads folder. On condition that you remember to restore the default folder after the operation.
- Combines perfectly with LinkClump,
- You don’t have to do anything but press download to get your data.
- Be careful not to load too many URLs each time. When it crashes, it crashes well.
#5. Google Spreadsheets: under 1000 rows, but with some complicated elements to retrieve
Here again, a rather “silly” use case, but Google Spreadsheets allows you to do a lot of things thanks to the ImportXML function. Thanks to the XPath syntax (very important in webscraping, and not specific to this use by Google Spreadsheets), you can obtain any element of a web page very easily.
You can scrap quite easily using xPath, Google Sheets and the =importxml function. Although not widely used, xPath queries can be used to retrieve structured data from the content of web pages.
You can, for example, retrieve all the H2 titles of the article you are reading by writing =importxml(“https://salesdorado.com/automatisation/meilleurs-outils-webscraping/”, “//h2”) to a cell in a Google Sheets spreadsheet.
This is what is used in Salesdorado’s lead scorer to get the title of the domain homepage associated with a contact’s email address.
Salesdorado’s advice
Note that using a Spreadsheet opens the door to dynamic processes to refresh or enrich your data dynamically.
- Much more flexible
- Can be used in flow (not just batch)
- Requires knowledge of Xpath (can be acquired fairly quickly).
- Hardly viable beyond 1000 lines.
#6. WebScraper: for novices tackling large chunks (over 1000 lines)
Webscraper is a no-code tool, quite simple to use, which actually allows you to go quite far. You will have to be patient to create the patterns and the execution of the scrapping itself is … very slow. But the result is there, the tutorials are easy to learn (even without having written a line of code in your life), and you can do more serious things:
- Pagination,
- Interactions with the page, etc.
- Simple to use and quite powerful
- No Xpath to write
- Quite slow, both to set up, and to run
#7. SpiderPro: for novices with $38 to spare
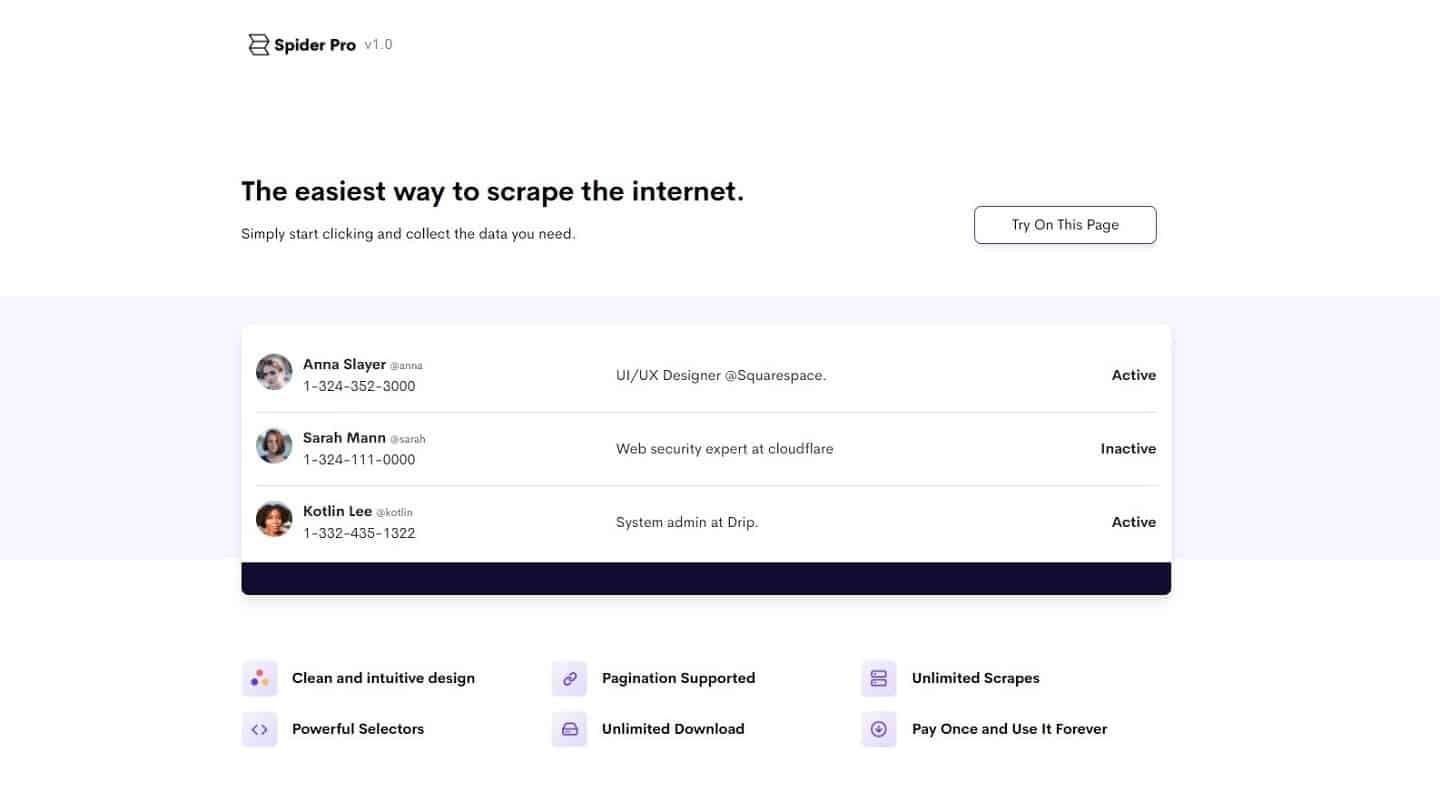
Spider Pro is one of the easiest to use tools for scraping the Internet. Simply click on what you are interested in to turn websites into organised data, which you can then download in JSON / CSV format. A perfect tool to automate your business prospecting. It’s similar to Webscraper with one difference: downloading Spider Pro will cost you $38 (one-time payment).
- Very easy to use
- Much faster to set up than webScraper
- It is a paying tool
#8. Apify : to scrape between 1000 and 10000 lines – Little web culture required (no-code)
We have already mentionedApify in our email prospecting tools, for the Salesdoradoemail finder.
Apify is a platform that allows you to execute code on a medium scale, without having to manage anything on the server setup. Sometimes superfluous, but often valuable to avoid IP rotation logic etc. Above all, there is a very complete library of what they call “actors” – i.e. pre-configured bots for the most common use cases. Thanks to Apify you :
- You will save a lot of time,
- Get performance that is unmatched by PhantomBuster (about 10 times faster on Apify in our experience),
- Spend very little.
In addition, Apify allows you to feed your bots into your processes (via their API) to enrich or refresh your datasets dynamically.
Note that you can use Apify for free for up to 10 hours per month. Apify offers a package at $49 per month for 100h machine where your data will be stored for 14 days. For $149 per month, you will have 400h machine. Finally, the Business package at $499 per month will give you 2000 machine hours per month.
- Easy to use,
- Will save you time
- Requires a fairly good web culture at least.
#9. Scrapy: to go fast, and hard

Scrapy is a bit of a reference for anyone who has ever written Python. It’s a framework that allows you to scrape quickly and easily. You can run it locally, on your servers / lambdas, or on scrapy cloud. The big limitation is for pages generated in Javascript, which is used more and more often. In this case, Scrapy recommends (precisely) to look for data sources directly using the “Network” of your browser.
The idea is that the page is indeed forced to execute a query to obtain the data to be displayed, and that it is in fact very often possible to make this query directly. However, this is not always possible. There is then a solution, much more cumbersome: execute the Javascript with a browser.
- A reference tool for Python enthusiasts
- Very effective & well documented framework
- Limit on pages generated in Javascript
#10. For larger projects: Puppeteer or Selenium
The problem of dynamically generated Javascript pages is more and more common, and if you can’t call the data source directly (usually 403), there is only one solution: use a browser. Remember to check that a bot has not already been written by someone on Apify (or elsewhere), it works quite regularly and avoids problems.
For that, at Salesdorado, we use Puppeteer in NodeJS because it is very simple to write and remarkably well documented. Python lovers will rather go to Selenium. For the execution, you have two options:
- You call a lot of sites, a few times each: find a place with good Internet speed, and run everything locally. You’ll save hours of trouble, and a few dollars.
- You call one site, many times: this is the most annoying case, and the most common too. Look at AWS Lambda to handle IP rotation without having to do it (lambdas use a different IP for each run, below a certain call frequency). For small projects, Apify can be an option, but it can get expensive quickly.
- Powerful, allows to pass on almost all the sites
- Costly to set up (in time or money).
- Prerequisite knowledge





