
The performance of your marketing & CRM actions depends to a large extent on the quality of your customer databases. You must clean them up regularly. This means, among other things, de-duplicating your contacts. What is deduplication? Why is it important? How does it work? What tools? This is the subject of this article. At the end, as a bonus, we will present you with a small tutorial to deduplicate your contacts in SQL.
Sommaire
Deduplication: an essential step in your data quality CRM
Deduplication and deduplication is a key step in any Data Quality Management approach. We will see why it is so important, what the difference is between deduplication and deduplication, and what the typical approaches to deduplication are.
Why is deduplication so important?
Deduplication consists of identifying data that appears in several files in the information system and keeping it in a single file by merging. In the context of database management, it is most often a matter of deduplicating contacts.
An information system such as CRM, for example, necessarily tends to generate duplicate contacts in several different places in the system. For at least 4 reasons:
- People who manage CRM sometimes add contacts or create accounts without necessarily checking whether or not they have already been registered in the system. Even if your CRM sends notifications when there is a duplication, not everyone pays attention – and the notifications don’t always display well on mobile.
- Data import tools do not always identify duplications very well.
- Integrations with external data sources such as website forms, partner portals or email brokers do not always require the CRM data before importing the new data.
- Many human errors or software bugs (bugs in the CRM or associated applications/tools) can easily result in hundreds or thousands of duplications.
Having 2% duplicate data is not a tragedy, as long as it is short-lived data and your tools and processes allow you to detect and correct it. Beyond 5% duplication, things get worse. This is where users start to complain, where reporting leads to false analysis.
Detecting and correcting duplicate data is a time-consuming task that requires methodological rigour. You need to choose the right duplicate data detection tools, use them well, identify from them the main reasons why your IS generates duplicate data and from this understanding dry up the main sources of duplicate creation.
Having an information system with as little duplicated data as possible allows :
- Have a cleaner database: deduplication is a key step in database cleanup.
- Reduce the maintenance and storage costs of your system.
- Reduce the cost of sending your campaigns and more broadly all marketing costs.
- Improve the customer experience > There is nothing more annoying for a customer than to be targeted several times by the same action, campaign or marketing scenario. Deduplication avoids brand damage resulting from duplicate messages.
- Know your customers better by limiting the dispersion of data in several tables.
- Improve the reliability of reporting and decision-making based on it.
The increase in the number of data sources and the number of contact points tends to encourage the creation of duplicate data. When you use dozens of tools, databases and channels, the risk of a customer being recorded in several places in the system is not negligible. Hence the importance of addressing this issue!
Deduplication vs. deduplication
People often confuse deduplication with deduplication. However, these are two quite different things.
A “duplicate” is when information or data is present several times in the same database or file.
Duplicate data” is when the same data is present in several databases or files in the information system. The problem of duplicate data is a major one, particularly in the field of prospecting. When you use several different prospecting files, it can easily happen that a contact is present in several files. In this case, data deduplication makes it possible to avoid contacting the same prospect several times.
However, this distinction should not be absolutized. What duplication and deduplication have in common is that they result in the presence of two identical contacts/data in the information system. In a unified IS with UC, deduplication and deduplication are quite similar.
What are the traditional approaches to deduplication?
The creation of duplicate data is often linked to syntactic differences resulting from input errors by sales staff or customer advisers, inversions, the use of abbreviations (for postal addresses, for example), etc. The data entered in the contact form, in the account creation form, or during an exchange with customer service are not strictly identical, which leads to duplicate data in the system, in the CRM for example.
Data is a living thing, most of it is bound to change over time: the individual moves, changes phone number, changes surname (marriage, divorce…), etc. This can also contribute to the creation of duplicates. This can also contribute to the creation of duplicates. In this case, the company must set up rules of priority between data sources to identify the "good" data, the one that is most likely to be true > and therefore the one to use.
Discover 10 tips for building optimised Landing Pages for lead collection.
Information system users are usually able to quickly identify information associated with an individual, to spot the identity of the contact behind syntactic differences. However, once a certain volume of data is reached, it becomes essential to use automation mechanisms to detect and correct these differences and remove duplicate data. Here are the main steps in the process:
Step 1: Data Management
- RNVP (Restructuring, Normalisation, Postal Validation) processing of postal addresses
- Standardisation of telephone numbers.
- Etc.
Second step: The implementation of an algorithm to calculate a proximity score, and this for each type of data: name, first name, postal address, email, telephone… Two methods are possible:
- A string similarity analysis and the use of distance calculations: Levenstein, Hamming…
- A sound similarity analysis, which consists of comparing the content of the data from a phonetic point of view. The metaphone and double metaphone methods are widely used for this purpose.
Third step: The calculation of a global similarity score of the database. This is where a machine learning model comes into play to build a composite similarity indicator. Random forest type methods can be usefully implemented at this level.
Which tool should you use to deduplicate your customer data?
We are now going to introduce you to 3 very good tools to deduplicate your customer data.
Octolis
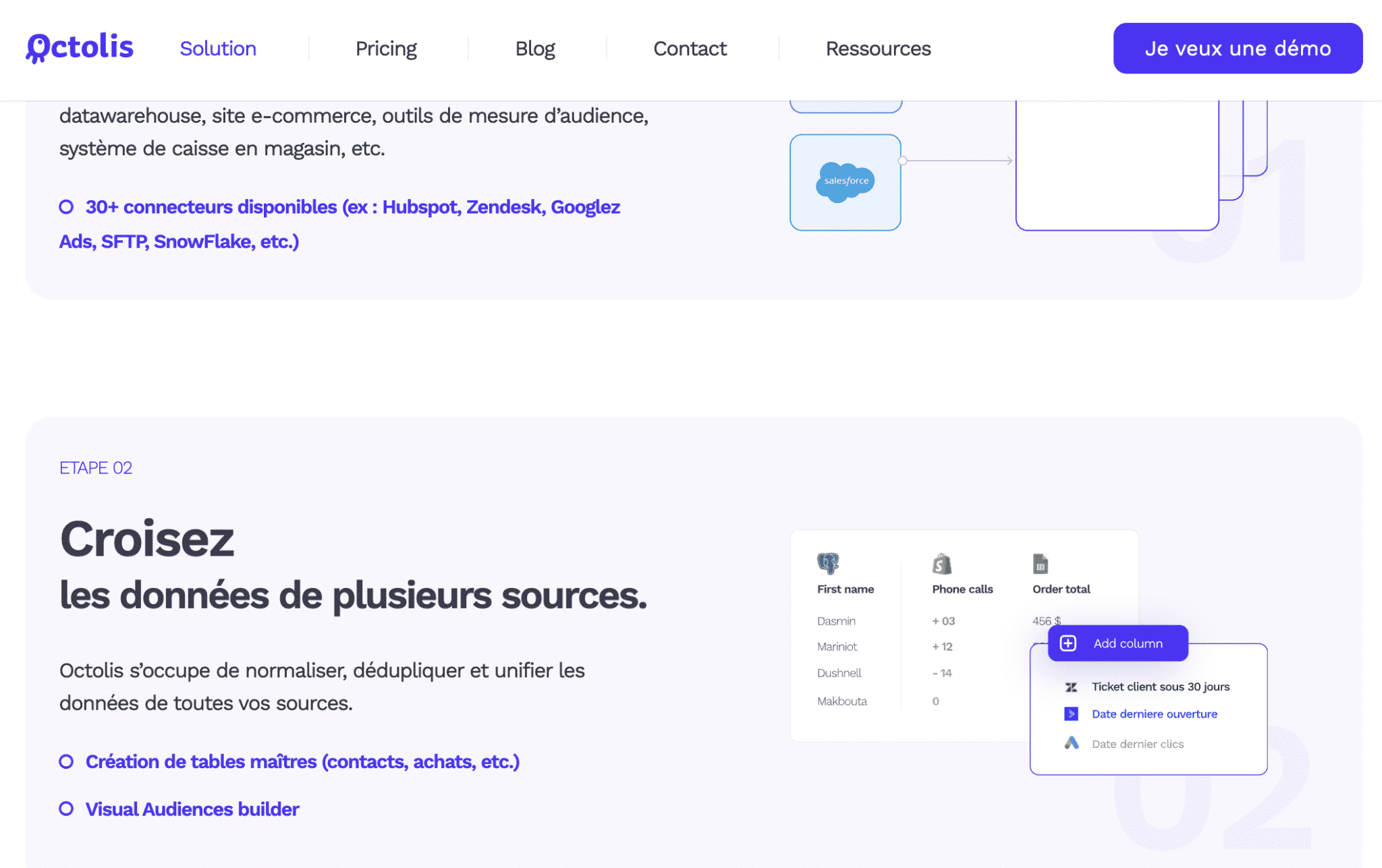
Octolis is a lightweight Customer Data Platform (CDP) designed to connect your data sources, clean them, de-duplicate them, unify them and enrich them. From there, the tool offers you the possibility to create audiences, scores, segments, aggregates that you can then synchronise in a few clicks in your Sales and Marketing tools for your activation use cases.
Unlike traditional CDPs, Octolis is independent of your customer database (your data warehouse) and gives you total control over your database.
The tool deduplicates contacts and companies using several keys, by default: the userId, or Last Name x First Name x Email or Last Name x First Name x Phone. The Octolis team can, if necessary, set up new keys on request.
DQE Software
Founded in 2008, DQE Software is a solution provider specialising in data quality management and the implementation of unique customer repositories. DQE has developed several intelligent technologies for optimising customer data quality, covering the entire chain from data collection to marketing activation. DQE solutions are available in cloud mode (SaaS) or as hosted versions on company servers. They are designed to interface easily with CRM and ERP tools. With more than 150,000 users and an annual growth rate of +20%, DQE Software is a reference in the market.
Discover our Top B2B CRM & Marketing software with free version.
Amabis

With offices in France and Morocco, Amabis is a French company that has been operating in the customer data management market for over 20 years. The company has nearly 500 customers. Historically, Amabis was specialized in the management of CRM & marketing databases (AmaBase), which allowed it to acquire a strong expertise in the management of customer data and become a leading player in the world of Data Quality Management. Amabis has been offering a new CRM solution since 2015, AmaCRM, which natively integrates data quality management.
What if you learned to deduplicate yourself in SQL?
Did you know that it is possible to deduplicate customer data from your relational database using a “simple” SQL query? We have taken some screenshots to quickly explain the logic. The query we are going to present to you allows you to transform a table of contacts into a single customer repository (UCR). Here is the result:
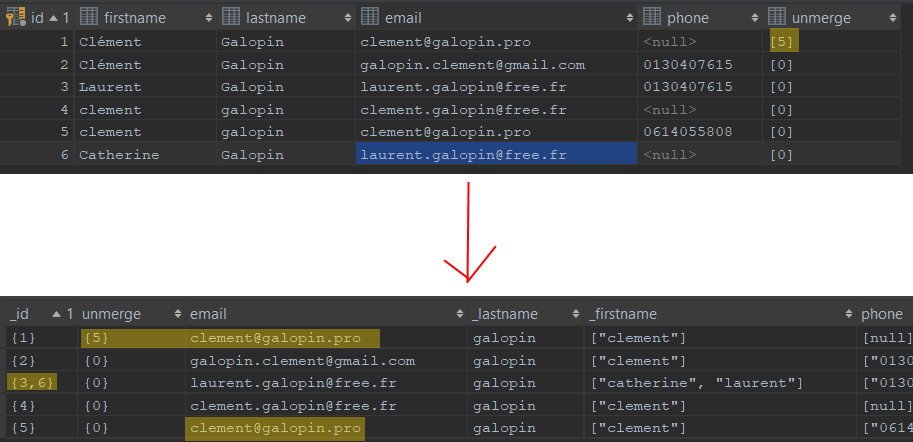
The first capture shows the table before the SQL query is executed, the second the table after the query is executed.
This query, as you can see, takes into account unmerging rules, so that two wrongly associated contacts can be dissociated a posteriori. This is very practical. In this case, it prevents two members of the same family from being associated because of the identity of the name. Remember that deduplication is the process that consists of merging identical contacts in your databases. In this process, one of the biggest risks is to merge contacts that are not identical. Unmerging rules act as safeguards. If you decide to de-duplicate your contacts in SQL, we strongly recommend that you implement these rules.
Discover our complete guide to the art of identifying anonymous visitors to a B2B website.
The other interest of this SQL query is that it succeeds in making a fuzzyjoin on the first name by assimilating the accented / unaccented first names and the first names with / without capital letters > Clément = clement. Remember that spelling/syntactic differences are the main source of duplicates. Here is the query:
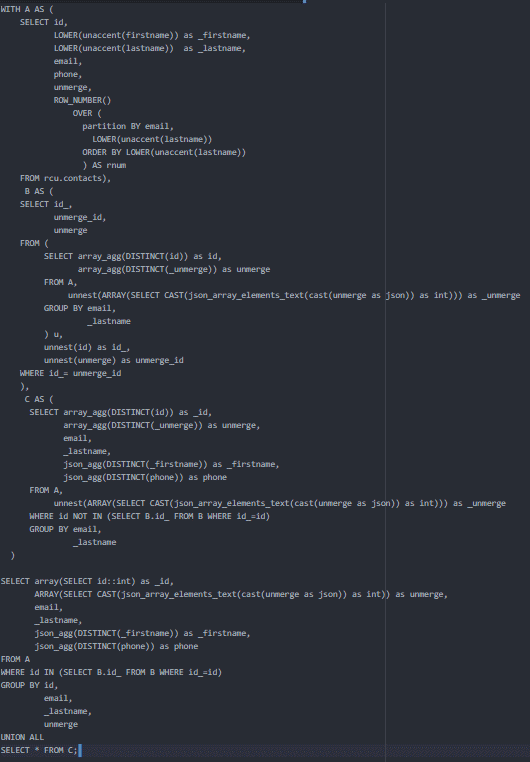
We have taken the time to detail each of the parts it contains, to help you better understand the logic.
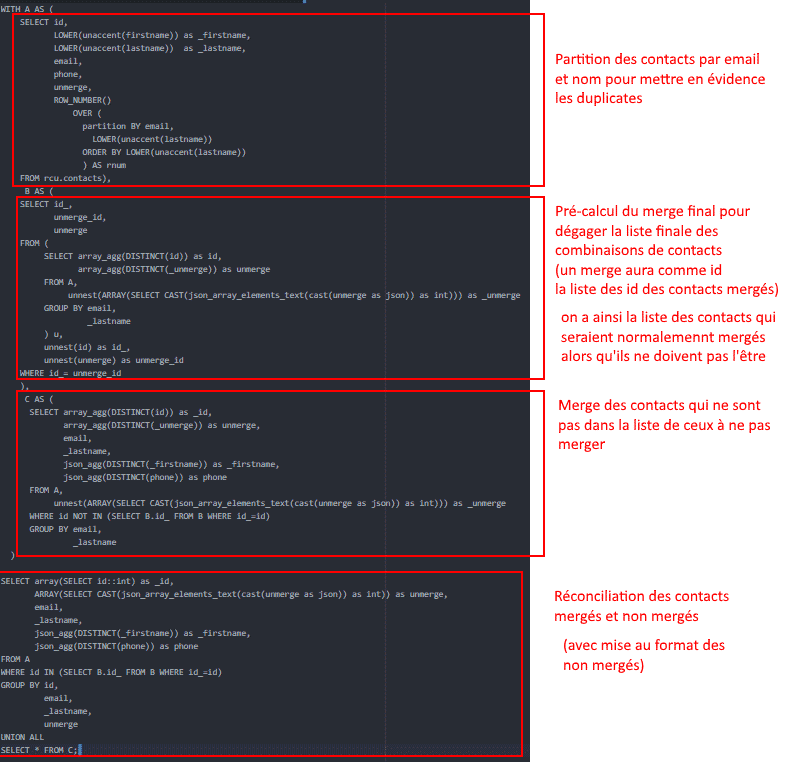
If you are familiar with SQL and relational database management, you can deduplicate your customer data in SQL. This is what we wanted to show you in this small example.
Are you a marketer and not at all comfortable with SQL? We invite you to discover the fundamentals of SQL for marketers.




