
El rendimiento de sus acciones de marketing y CRM depende en gran medida de la calidad de sus bases de datos de clientes. Hay que limpiarlos regularmente. Esto significa, entre otras cosas, desduplicar tus contactos. ¿Qué es la deduplicación? ¿Por qué es importante? ¿Cómo funciona? ¿Qué herramientas? Este es el tema de este artículo. Al final, como bonus, te presentaremos un pequeño tutorial para deduplicar tus contactos en SQL.
Sommaire
Deduplicación: un paso esencial en su CRM de calidad de datos
La deduplicación y la deduplicación es un paso clave en cualquier enfoque de gestión de la calidad de los datos. Veremos por qué es tan importante, cuál es la diferencia entre deduplicación y desduplicación, y cuáles son los enfoques típicos de la deduplicación.
¿Por qué es tan importante la deduplicación?
La deduplicación consiste en identificar los datos que aparecen en varios archivos del sistema de información y mantenerlos en un único archivo mediante la fusión. En el contexto de la gestión de bases de datos, lo más frecuente es que se trate de desduplicar los contactos.
Un sistema de información como el CRM, por ejemplo, tiende necesariamente a generar contactos duplicados en varios lugares diferentes del sistema. Por al menos 4 razones:
- Las personas que gestionan el CRM a veces añaden contactos o crean cuentas sin comprobar necesariamente si ya están registrados en el sistema. Incluso si su CRM envía notificaciones cuando hay una duplicación, no todo el mundo presta atención, y las notificaciones no siempre se muestran bien en el móvil.
- Las herramientas de importación de datos no siempre identifican bien las duplicaciones.
- Las integraciones con fuentes de datos externas, como formularios de sitios web, portales de socios o corredores de correo electrónico, no siempre requieren los datos del CRM antes de importar los nuevos datos.
- Muchos errores humanos o de software (fallos en el CRM o en las aplicaciones/herramientas asociadas) pueden dar lugar fácilmente a cientos o miles de duplicaciones.
Tener un 2% de datos duplicados no es una tragedia, siempre y cuando sean datos de corta duración y sus herramientas y procesos le permitan detectarlos y corregirlos. Por encima del 5% de duplicación, las cosas empeoran. Aquí es donde los usuarios empiezan a quejarse, donde los informes dan lugar a falsos análisis.
Detectar y corregir los datos duplicados es una tarea que requiere mucho tiempo y rigor metodológico. Hay que elegir las herramientas de detección de datos duplicados adecuadas, utilizarlas bien, identificar a partir de ellas las principales razones por las que su SI genera datos duplicados y a partir de esta comprensión secar las principales fuentes de creación de duplicados.
Disponer de un sistema de información con el menor número posible de datos duplicados permite :
- Tener una base de datos más limpia: la deduplicación es un paso clave en la limpieza de la base de datos.
- Reduzca los costes de mantenimiento y almacenamiento de su sistema.
- Reduzca los costes de envío de sus campañas y, en general, todos los costes de marketing.
- Mejorar la experiencia del cliente > No hay nada más molesto para un cliente que ser objeto varias veces de la misma acción, campaña o escenario de marketing. La deduplicación evita los daños a la marca derivados de los mensajes duplicados.
- Conozca mejor a sus clientes limitando la dispersión de datos en varias tablas.
- Mejorar la fiabilidad de los informes y la toma de decisiones basada en ellos.
El aumento del número de fuentes de datos y del número de puntos de contacto tiende a fomentar la creación de datos duplicados. Cuando se utilizan decenas de herramientas, bases de datos y canales, el riesgo de que un cliente quede registrado en varios lugares del sistema no es despreciable. De ahí la importancia de abordar esta cuestión.
Deduplicación vs. deduplicación
La gente suele confundir la deduplicación con la desduplicación. Sin embargo, son dos cosas muy diferentes.
Un “duplicado” es cuando la información o los datos están presentes varias veces en la misma base de datos o archivo.
Se habla de “datos duplicados” cuando los mismos datos están presentes en varias bases de datos o archivos del sistema de información. El problema de la duplicación de datos es importante, sobre todo en el ámbito de la prospección. Cuando se utilizan varios ficheros de prospección diferentes, puede ocurrir fácilmente que un contacto esté presente en varios ficheros. En este caso, la deduplicación de datos permite evitar contactar varias veces con el mismo cliente potencial.
Sin embargo, esta distinción no debe absolutizarse. Lo que tienen en común la duplicación y la deduplicación es que dan lugar a la presencia de dos contactos/datos idénticos en el sistema de información. En un SI unificado con UC, la deduplicación y la desduplicación son bastante similares.
¿Cuáles son los enfoques tradicionales de la deduplicación?
La creación de datos duplicados suele estar relacionada con diferencias sintácticas derivadas de errores de introducción por parte del personal de ventas o de los asesores de clientes, inversiones, uso de abreviaturas (para las direcciones postales, por ejemplo), etc. Los datos introducidos en el formulario de contacto, en el formulario de creación de cuentas o durante un intercambio con el servicio de atención al cliente no son estrictamente idénticos, lo que provoca la duplicación de datos en el sistema, en el CRM por ejemplo.
Los datos son algo vivo, la mayoría de ellos están destinados a cambiar con el tiempo: el individuo se muda, cambia de número de teléfono, cambia de apellido (matrimonio, divorcio…), etc. Esto también puede contribuir a crear duplicados. Esto también puede contribuir a la creación de duplicados. En este caso, la empresa debe establecer reglas de prioridad entre las fuentes de datos para identificar los datos “buenos”, los que tienen más probabilidades de ser verdaderos > y, por tanto, los que hay que utilizar.
Descubra 10 consejos para crear páginas de aterrizaje optimizadas para la captación de clientes potenciales.
Los usuarios de los sistemas de información suelen ser capaces de identificar rápidamente la información asociada a una persona, para descubrir la identidad del contacto tras las diferencias sintácticas. Sin embargo, cuando se alcanza un determinado volumen de datos, se hace imprescindible utilizar mecanismos de automatización para detectar y corregir estas diferencias y eliminar los datos duplicados. He aquí las principales etapas del proceso:
Paso 1: Gestión de datos
- Tratamiento de direcciones postales RNVP (Reestructuración, Normalización, Validación Postal)
- Normalización de los números de teléfono.
- Etc.
Segundo paso: La implementación de un algoritmo para calcular una puntuación de proximidad, y esto para cada tipo de datos: nombre, apellido, dirección postal, correo electrónico, teléfono… Son posibles dos métodos:
- Un análisis de similitud de cadenas y el uso de cálculos de distancia: Levenstein, Hamming…
- Un análisis de similitud de sonidos, que consiste en comparar el contenido de los datos desde el punto de vista fonético. Los métodos de metafonía y doble metafonía son muy utilizados para este fin.
Tercer paso: el cálculo de una puntuación de similitud global de la base de datos. Aquí es donde entra en juego un modelo de aprendizaje automático para construir un indicador de similitud compuesto. Los métodos de tipo bosque aleatorio pueden ser útiles en este nivel.
¿Qué herramienta debe utilizar para deduplicar los datos de sus clientes?
Ahora vamos a presentarle 3 muy buenas herramientas para desduplicar los datos de sus clientes.
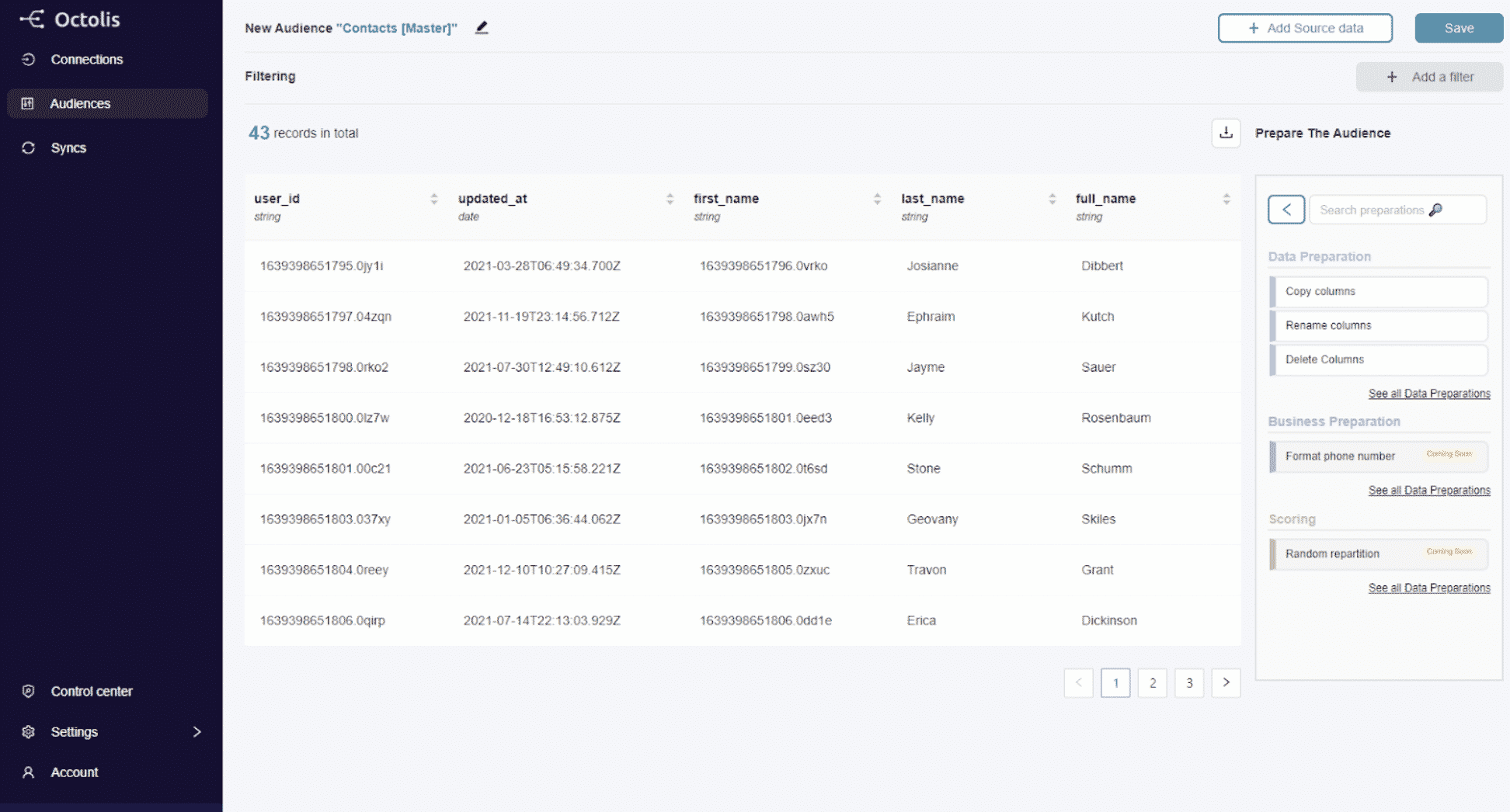
Octolis
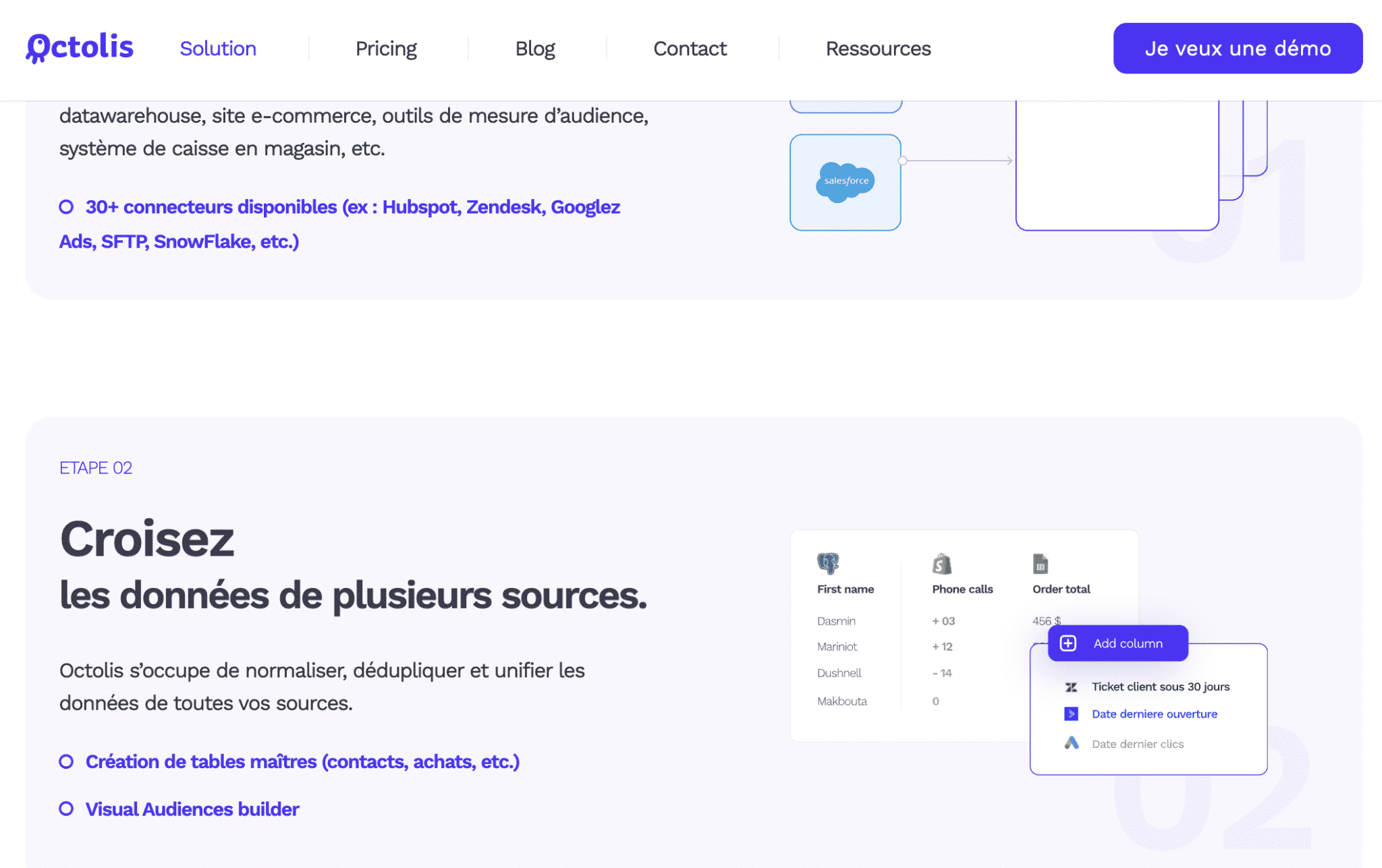
Octolis es una plataforma ligera de datos de clientes (CDP) diseñada para conectar sus fuentes de datos, limpiarlas, desduplicarlas, unificarlas y enriquecerlas. A partir de ahí, la herramienta le ofrece la posibilidad de crear audiencias, puntuaciones, segmentos, agregados que luego puede sincronizar en unos pocos clics en sus herramientas de Ventas y Marketing para sus casos de uso de activación.
A diferencia de los CDP tradicionales, Octolis es independiente de su base de datos de clientes (su almacén de datos) y le ofrece un control total sobre su base de datos.
La herramienta deduplica los contactos y las empresas utilizando varias claves, por defecto: el userId, o Apellido x Nombre x Email o Apellido x Nombre x Teléfono. El equipo de Octolis puede, si es necesario, establecer nuevas llaves a petición.
Software DQE
Fundada en 2008, DQE Software es un proveedor de soluciones especializado en la gestión de la calidad de los datos y en la implantación de repositorios únicos de clientes. DQE ha desarrollado varias tecnologías inteligentes para optimizar la calidad de los datos de los clientes, cubriendo toda la cadena desde la recogida de datos hasta la activación del marketing. Las soluciones DQE están disponibles en modo nube (SaaS) o como versiones alojadas en los servidores de la empresa. Están diseñados para interactuar fácilmente con las herramientas de CRM y ERP. Con más de 150.000 usuarios y una tasa de crecimiento anual del +20%, DQE Software es una referencia en el mercado.
Descubra nuestro software Top B2B CRM & Marketing con versión gratuita.
Amabis

Con oficinas en Francia y Marruecos, Amabis es una empresa francesa que opera en el mercado de la gestión de datos de clientes desde hace más de 20 años. La empresa tiene casi 500 clientes. Históricamente, Amabis se ha especializado en la gestión de bases de datos de CRM y marketing (AmaBase), lo que le ha permitido adquirir una gran experiencia en la gestión de datos de clientes y convertirse en un actor principal en el mundo de la gestión de la calidad de datos. Amabis ofrece desde 2015 una nueva solución CRM, AmaCRM, que integra de forma nativa la gestión de la calidad de los datos.
¿Y si aprendes a deduplicarte en SQL?
¿Sabía que es posible deduplicar los datos de los clientes de su base de datos relacional mediante una “simple” consulta SQL? Hemos tomado algunas capturas de pantalla para explicar rápidamente la lógica. La consulta que le vamos a presentar permite transformar una tabla de contactos en un repositorio único de clientes (UCR). Aquí está el resultado:
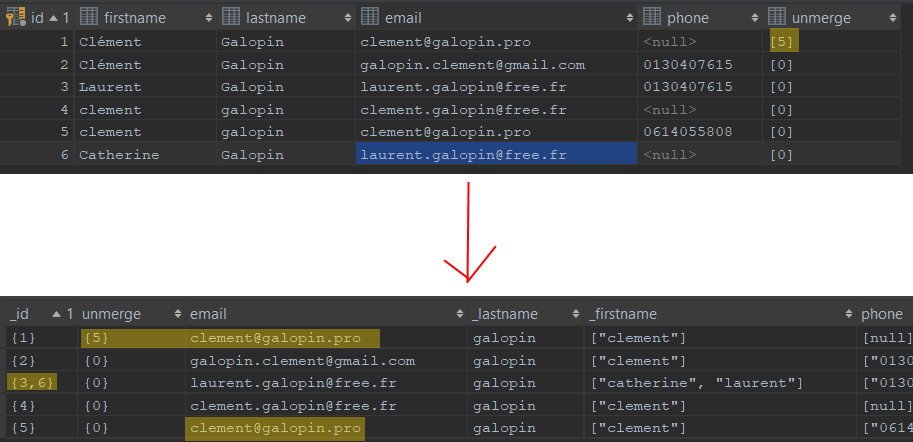
La primera captura muestra la tabla antes de ejecutar la consulta SQL, la segunda la tabla después de ejecutar la consulta.
Esta consulta, como se puede ver, tiene en cuenta las reglas de no fusión, de modo que dos contactos erróneamente asociados pueden ser disociados a posteriori. Esto es muy práctico. En este caso, impide que se asocien dos miembros de la misma familia por la identidad del nombre. Recuerde que la deduplicación es el proceso que consiste en fusionar contactos idénticos en sus bases de datos. En este proceso, uno de los mayores riesgos es fusionar contactos que no son idénticos. Las normas de separación actúan como salvaguardias. Si decide desduplicar sus contactos en SQL, le recomendamos encarecidamente que aplique estas reglas.
Descubra nuestra guía completa sobre el arte de identificar a los visitantes anónimos de un sitio web B2B.
El otro interés de esta consulta SQL es que consigue hacer un fuzzyjoin sobre el nombre asimilando los nombres acentuados / no acentuados y los nombres con / sin mayúsculas > Clément = clement. Recuerde que las diferencias ortográficas/sintácticas son la principal fuente de duplicados. Esta es la consulta:
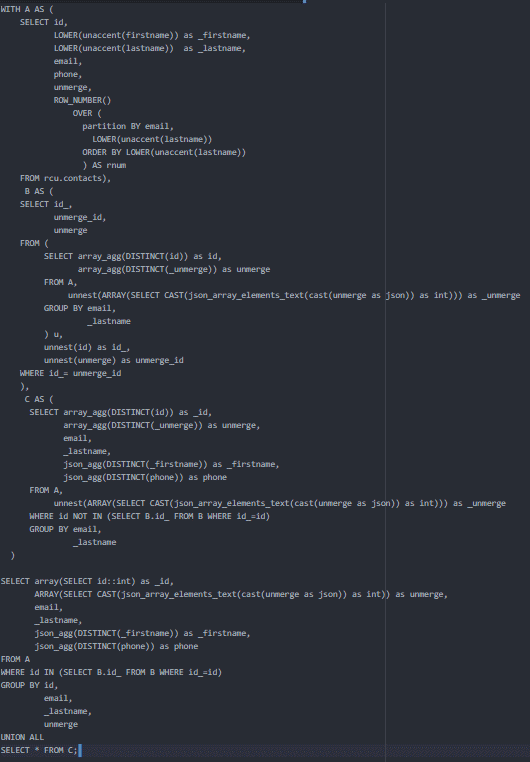
Nos hemos tomado el tiempo de detallar cada una de las partes que contiene, para ayudarle a entender mejor la lógica.
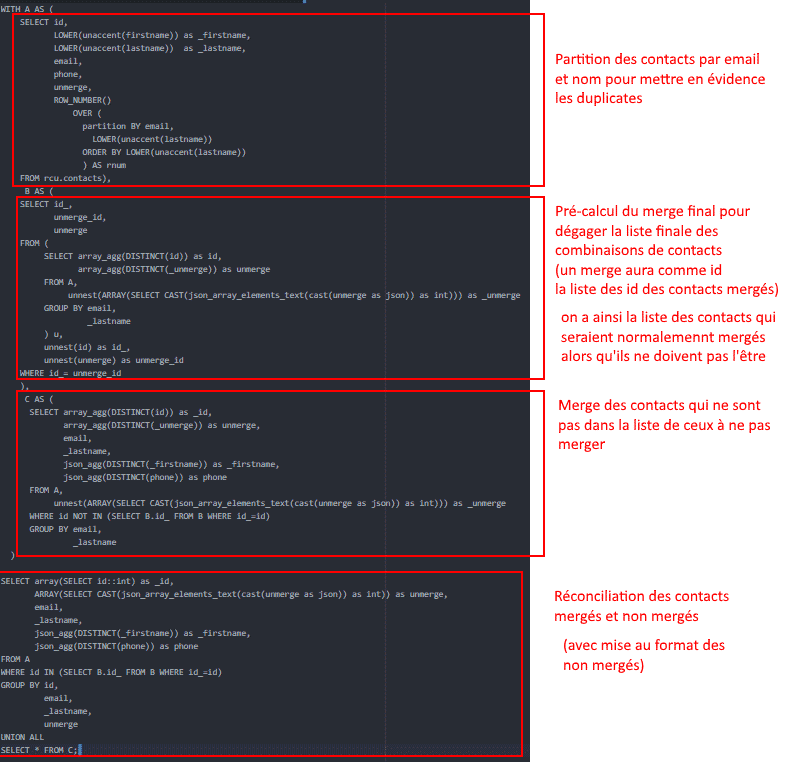
Si está familiarizado con SQL y la gestión de bases de datos relacionales, puede desduplicar los datos de sus clientes en SQL. Esto es lo que queríamos mostrarte en este pequeño ejemplo.




