
La performance de vos actions marketing & CRM repose en bonne partie sur la qualité de vos bases de données clients. Vous devez les nettoyer régulièrement. Ce qui, entre autres, passent par un travail de déduplication / dédoublonnages des contacts. Qu’est-ce que c’est ? Pourquoi c’est important ? Comment ça marche ? Quels outils ? C’est l’objet de cet article. A la fin, en bonus, nous vous présenterons un petit tutoriel pour dédupliquer vos contacts en SQL.
Sommaire
Pourquoi la déduplication est si importante ?
La déduplication consiste à identifier les données qui apparaissent dans plusieurs fichiers du système d’information et à les conserver dans un seul fichier par fusion (ou merging en anglais). Dans le cadre de la gestion de bases de données, il s’agit pour la plupart du temps de dédupliquer des contacts.
Un système d’information de type CRM par exemple a nécessairement tendance à engendrer des duplications de contacts dans plusieurs endroits différents du système.
Les causes de la duplication des données
Pour au moins 4 raisons :
- Les personnes qui gèrent le CRM ajoutent parfois des contacts ou créent des comptes sans forcément vérifier s’ils ont déjà été enregistrés ou non dans le système. Même si votre CRM envoie des notifications en cas de duplication, tout le monde n’y fait pas attention – et les notifications ne s’affichent pas toujours très bien sur mobile.
- Les outils d’import de données n’identifient pas toujours très bien les duplications.
- Les intégrations avec des sources externes de données comme les formulaires de site web, les portails partenaires ou les brokers emails ne requêtent pas toujours les données du CRM avant d’importer les nouvelles données.
- Beaucoup d’erreurs humaines ou de bugs logiciels (bugs du CRM ou des applications / outils associés) peuvent facilement engendrer des centaines ou des milliers de duplications.
L’impact des données dupliquées
Avoir 2% de données dupliquées n’est pas un drame, tant qu’il s’agit de données à courte durée de vie et que vos outils et process permettent de les détecter et de les corriger. Au-delà de 5% de duplications, les choses se gâtent.
C’est à partir de ce seuil que les utilisateurs commencent à se plaindre, que les reportings conduisent à de fausses analyses.
Détecter et corriger les données dupliquées est un travail qui prend du temps et qui demande une grande rigueur méthodologique.
Vous devez choisir les bons outils de détection de données dupliquées, bien les utiliser, identifier à partir d’eux les principales raisons pour lesquelles votre SI génère des données dupliquées et tarir à partir de cette compréhension les principales sources de création de duplications.
Les avantages de la déduplication des données
Disposer d’un système d’information avec le moins de données dupliquées possibles permet :
- D’avoir une base de données plus propre : la déduplication est une étape clé du nettoyage de BDD.
- De réduire les coûts de maintenance et de stockage de votre système.
- De réduire les coûts d’envoi de vos campagnes et plus largement tous les coûts marketing.
- D’améliorer l’expérience client > Il n’y a rien de plus agaçant pour un client que de se voir ciblé plusieurs fois par une même action, campagne ou scénario marketing. La déduplication permet d’éviter une dégradation de l’image de marque résultant de l’envoi de doublons de messages.
- De mieux connaître vos clients en limitant la dispersion des données dans plusieurs tables.
- D’améliorer la fiabilité des reportings et les prises de décision basées sur eux.
L’augmentation du nombre de sources de données et du nombre de points de contact a tendance à favoriser la création de données dupliquées. Lorsque l’on utilise des dizaines d’outils, de bases et de canaux, le risque qu’un client se retrouve recensé dans plusieurs endroits du système n’est pas négligeable. D’où l’importance de se saisir du sujet !
Déduplication vs Dédoublonnage
On confond souvent déduplication et dédoublonnage. Ce sont pourtant deux choses assez différentes.
On parle de « doublon » lorsqu’une information, une donnée est présente plusieurs fois dans une même base de données ou dans un même fichier.
On parle de « donnée dupliquée », lorsqu’une même donnée est présente dans plusieurs bases ou fichiers du système d’information. La problématique des données dupliquées est majeure notamment dans le domaine de la prospection. Lorsque vous utilisez plusieurs fichiers de prospection différents, il peut facilement arriver qu’un contact soit présent dans plusieurs fichiers. Dans ce cas, la déduplication des données permet d’éviter de contacter plusieurs fois un même prospect.
Malgré tout, il ne faut absolutiser cette distinction. Le point commun entre la duplication et le doublon est qu’elle a pour effet d’engendrer la présence de deux contacts/données identiques dans le système d’information. Dans un SI unifié avec RCU, les opérations de dédoublonnage et de déduplication sont assez proches.
Quelles sont les approches classiques en matière de déduplication ?
La création de données dupliquées est souvent liée à des différences syntaxiques résultant d’erreurs de saisie, d’inversions, de l’utilisation d’abréviations, ou encore de l’évolution naturelle des données dans le temps (déménagement, changement de nom, etc.). Pour gérer efficacement ces problématiques à grande échelle, il est indispensable de mettre en place des mécanismes d’automatisation.
Voici les principales étapes d’une démarche classique de déduplication :
#1 Normalisation et validation des données
La première étape consiste à restructurer et normaliser les données pour faciliter leur comparaison. Cela inclut par exemple :
- Le traitement RNVP (Restructuration, Normalisation, Validation Postale) des adresses
- La normalisation des numéros de téléphone
- La mise en majuscules ou minuscules des chaînes de caractères
- La suppression des accents et caractères spéciaux
L’objectif, vous l’aurez compris, est d’harmoniser au maximum le format des données pour limiter les variations syntaxiques.
#2 Calcul des scores de similarité
La deuxième étape vise à évaluer le degré de similarité entre les enregistrements, pour chaque type de donnée (nom, prénom, adresse, email, téléphone…).
Deux approches sont possibles :
- L’analyse de similarité des chaînes de caractères, en utilisant des algorithmes de calcul de distance comme Levenshtein ou Hamming. Ces algorithmes mesurent le nombre de modifications requises pour passer d’une chaîne à une autre.
- L’analyse de similarité phonétique, qui consiste à comparer les données d’un point de vue sonore plutôt que textuel. Des algorithmes comme Soundex, Metaphone ou Double Metaphone sont fréquemment employés dans ce cas.
Ces scores de similarité permettent d’identifier les enregistrements qui, malgré des différences syntaxiques, ont de fortes probabilités de concerner une même entité.
#3 Calcul d’un score de similarité global
La dernière étape consiste à combiner les différents scores de similarité (nom, prénom, adresse…) pour obtenir un score global au niveau de chaque paire d’enregistrements. Ce score reflète la probabilité que deux enregistrements correspondent à un doublon.
Les modèles de machine learning, comme les forêts aléatoires (random forests), sont souvent utilisés à ce stade pour analyser les scores de similarité et décider du seuil à partir duquel deux enregistrements doivent être considérés comme des doublons.
Une fois les doublons identifiés, l’étape suivante est la fusion des enregistrements (ou merging). Elle suppose la définition de règles pour déterminer, en cas de conflit, quelle source de données doit être privilégiée.
Quel outil utiliser pour dédupliquer vos données clients ?
Nous allons à présent vous présenter 2 très bons outils pour dédupliquer vos données clients.
DQE Software
Créé en 2008, DQE Software est un éditeur de solutions spécialisées dans la gestion de la Data Quality et la mise en place de référentiels clients uniques. DQE a développé plusieurs technologies intelligentes d’optimisation de la qualité des données clients, couvrant toute la chaîne allant de la collecte des données à leur activation marketing.
Les solutions DQE sont disponibles en mode cloud (SaaS) ou en versions hébergées sur les serveur de l’entreprise. Elles sont conçues pour s’interfacer facilement avec les outils CRM et ERP. Avec plus de 150 000 utilisateurs et une croissance annuelle de +20%, DQE Software est une référence sur le marché.
Découvrez notre Top des logiciels CRM & Marketing B2B avec version gratuite.
Amabis

Implanté en France et au Maroc, Amabis est un acteur français en exercice depuis plus de 20 ans sur le marché de la gestion de données clients. La société compte près de 500 clients.
Historiquement, Amabis était spécialisée dans l’infogérance de bases CRM & marketing (AmaBase), ce qui lui a permis d’acquérir une forte expertise dans la gestion des données clients et de devenir un acteur de premier plan dans l’univers du Data Quality Management. Amabis propose une nouvelle offre CRM depuis 2015, AmaCRM, qui intègre nativement la gestion de la Data Quality.
Quel prestataire choisir pour se faire accompagner dans la déduplication des données ?
La déduplication des données clients est un enjeu stratégique pour les entreprises, mais c’est aussi un chantier complexe qui nécessite des compétences pointues, à la fois techniques et métier.
Il est souvent pertinent de se faire accompagner par un prestataire externe pour mener à bien ce type de projet.
Voici quelques critères à prendre en compte pour choisir un bon prestataire :
- L’expérience et les références. Privilégiez un prestataire qui a déjà mené de nombreux projets de déduplication, idéalement dans votre secteur d’activité. C’est la base. N’hésitez pas d’ailleurs à demander des références et des cas clients similaires à votre entreprise/projet.
- La méthodologie et les outils. Le prestataire doit être en mesure de vous expliquer clairement sa méthodologie et les outils qu’il utilise. Donc, vérifiez que son approche est structurée, industrialisable et adaptée à vos volumes de données.
- L’accompagnement et le transfert de compétences. Au-delà de la prestation technique, il est vraiment important que le prestataire vous accompagne dans la prise en main de la solution et le transfert de compétences vers vos équipes. Un bon partenaire doit vous rendre autonome. C’est la finalité.
- La connaissance de votre écosystème d’outils. Idéalement, le prestataire doit avoir une bonne connaissance des outils que vous utilisez (CRM, outils de marketing automation, solutions data, etc.).
- La capacité à adresser les enjeux connexes. Un projet de déduplication s’inscrit souvent dans une démarche plus globale de qualité des données. Il n’existe d’ailleurs pas de prestataires uniquement axés sur la déduplication. Les prestataires que vous allez cibler, ce sont des prestataires data, qui peuvent adresser toute une série de problématiques data dont la déduplication n’est qu’une composante.
Besoin d’accompagnement pour votre projet data ?
Si vous cherchez un prestataire pour vous accompagner dans votre projet de déduplication et dans vos projets data en général, on vous recommande Cartelis. Cartelis est un cabinet de conseil expert en Data Marketing & CRM. Ils interviennent sur des projets data / data marketing auprès de PME, ETI et grands groupes, en utilisant une approche sur-mesure, agile – le tout basé sur une méthodologie maison dont ils ont seuls le secret.

Ils ont le gros avantage de combiner une forte expertise technique et une connaissance approfondie des enjeux métiers/business liés au marketing et au CRM. Ils sauront vous accompagner aussi bien dans le cadrage de votre projet data que dans la conception du dispositif et son déploiement technique.
Et si vous appreniez à dédupliquer vous-même en SQL ?
Saviez-vous qu’il est possible de dédupliquer les données clients de votre base de données relationnelle à partir d’une “simple” requête SQL ? Nous avons fait quelques captures d’écran pour vous expliquer rapidement la logique. La requête que nous allons vous présenter permet de transformer une table de contacts en référentiel client unique (RCU). Voici le résultat :
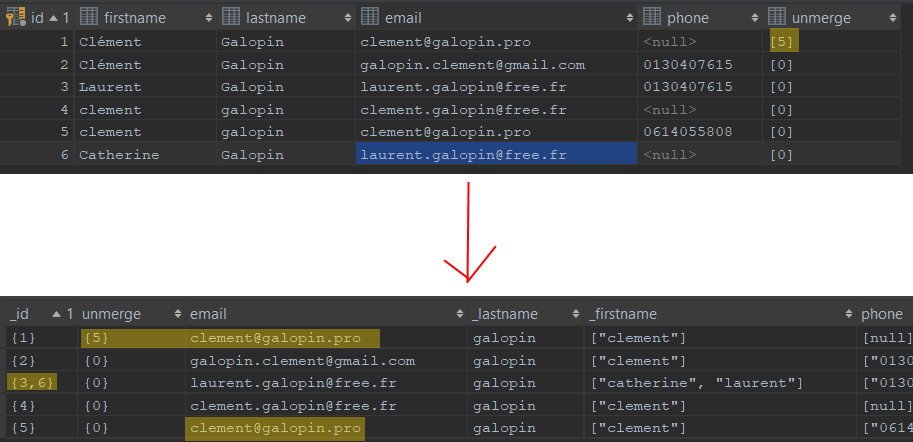
La première capture présente la table avant l’exécution de la requête SQL, la deuxième la table après l’exécution de la requête.
Cette requête, comme vous pouvez le voir, prend en compte des règles de unmerging, pour que deux contacts associés à tord puissent être dissociés a posteriori. C’est très pratique. Dans ce cas, cela permet d’éviter que deux membres d’une même famille soient associés à cause de l’identité du nom.
Rappelons que la déduplication est le process qui consiste à fusionner les contacts identiques qui se trouvent dans vos bases. Dans ce process, l’un des plus gros risques est de fusionner des contacts qui ne sont pas identiques. Les règles d’unmerging jouent le rôle de gardes-fous.
Si vous décidez de dédupliquer vos contacts en SQL, nous vous recommandons vivement de mettre en place ces règles.
Découvrez notre guide complet sur l’art d’identifier les visiteurs anonymes d’un site web en B2B.
L’autre intérêt de cette requête SQL est qu’elle réussi à faire un fuzzyjoin sur le prénom en assimilant les prénoms accentués / non accentués et les prénoms avec / sans majuscule > Clément = clement. Rappelons que les différences orthographiques / syntaxiques sont la principales sources de doublons.
Voici la requête :
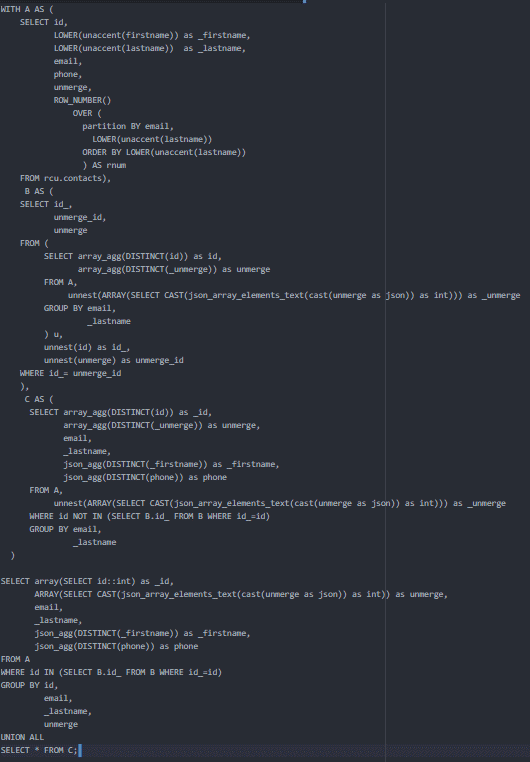
Nous avons pris le temps de détailler chacune des parties qu’elle contient, pour vous aider à mieux comprendre la logique.
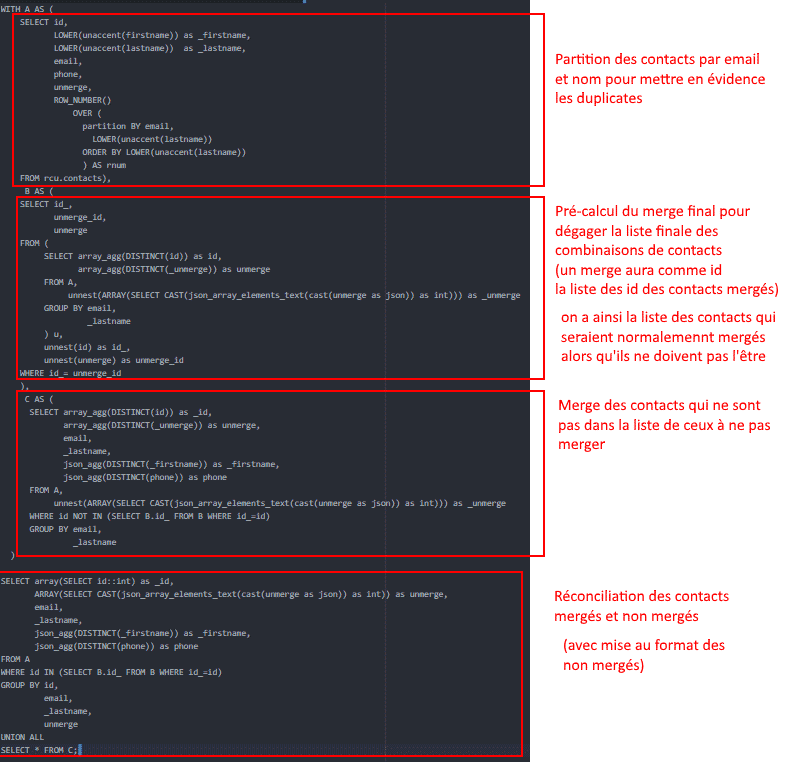
Si vous maîtrisez le langage SQL et la gestion de bases de données relationnelles, vous pouvez réaliser la déduplication de vos données clients en SQL. C’était ce que nous voulions vous montrer au travers ce petit exemple.






