O desempenho de suas ações de marketing & CRM depende em grande parte da qualidade de seus bancos de dados de clientes. Você deve limpá-los regularmente. Isto significa, entre outras coisas, a desduplicação de seus contatos. O que é desduplicação? Por que isso é importante? Como funciona? Que ferramentas? Este é o assunto deste artigo. No final, como um bônus, lhe apresentaremos um pequeno tutorial para deduplicar seus contatos em SQL.
Sommaire
Deduplicação: uma etapa essencial em sua CRM de qualidade de dados
Deduplicação e desduplicação é um passo fundamental em qualquer abordagem de Gerenciamento de Qualidade de Dados. Veremos porque é tão importante, qual é a diferença entre deduplicação e deduplicação, e quais são as abordagens típicas da deduplicação.
Por que a deduplicação é tão importante?
A deduplicação consiste em identificar dados que aparecem em vários arquivos no sistema de informação e mantê-los em um único arquivo por meio de fusão. No contexto da gestão de banco de dados, na maioria das vezes é uma questão de deduplicação de contatos.
Um sistema de informação como o CRM, por exemplo, tende necessariamente a gerar contatos duplicados em vários lugares diferentes do sistema. Por pelo menos 4 razões:
- As pessoas que administram CRM às vezes adicionam contatos ou criam contas sem necessariamente verificar se eles já foram registrados no sistema ou não. Mesmo que seu CRM envie notificações quando há uma duplicação, nem todos prestam atenção – e as notificações nem sempre são bem exibidas no celular.
- As ferramentas de importação de dados nem sempre identificam muito bem as duplicações.
- As integrações com fontes de dados externas como formulários de website, portais de parceiros ou corretores de e-mail nem sempre requerem os dados do CRM antes de importar os novos dados.
- Muitos erros humanos ou bugs de software (bugs no CRM ou aplicativos/ferramentas associados) podem facilmente resultar em centenas ou milhares de duplicações.
Ter 2% de dados duplicados não é uma tragédia, desde que sejam dados de curta duração e que suas ferramentas e processos lhe permitam detectá-los e corrigi-los. Acima de 5% de duplicação, as coisas pioram. É aqui que os usuários começam a reclamar, onde os relatórios levam a falsas análises.
A detecção e correção de dados duplicados é uma tarefa demorada que requer rigor metodológico. Você precisa escolher as ferramentas corretas de detecção de dados duplicados, utilizá-las bem, identificar a partir delas as principais razões pelas quais seu SI gera dados duplicados e a partir deste entendimento secar as principais fontes de criação de duplicados.
Ter um sistema de informação com o mínimo possível de dados duplicados permite :
- Ter um banco de dados mais limpo: a deduplicação é um passo fundamental na limpeza do banco de dados.
- Reduza os custos de manutenção e armazenamento do seu sistema.
- Reduza o custo de envio de suas campanhas e, mais amplamente, todos os custos de marketing.
- Melhorar a experiência do cliente > Não há nada mais irritante para um cliente do que ser visado várias vezes pela mesma ação, campanha ou cenário de marketing. A deduplicação evita danos de marca resultantes de mensagens duplicadas.
- Conheça melhor seus clientes, limitando a dispersão de dados em várias tabelas.
- Melhorar a confiabilidade dos relatórios e da tomada de decisões com base neles.
O aumento do número de fontes de dados e do número de pontos de contato tende a incentivar a criação de dados duplicados. Quando você utiliza dezenas de ferramentas, bancos de dados e canais, o risco de um cliente ser registrado em vários lugares do sistema não é desprezível. Daí a importância de abordar esta questão!
Deduplicação vs. deduplicação
As pessoas freqüentemente confundem a deduplicação com a deduplicação. Entretanto, estas são duas coisas bem diferentes.
Um “duplicado” é quando informações ou dados estão presentes várias vezes no mesmo banco de dados ou arquivo.
Dados duplicados” é quando os mesmos dados estão presentes em vários bancos de dados ou arquivos no sistema de informação. O problema da duplicação de dados é um dos principais, particularmente no campo da prospecção. Quando você utiliza vários arquivos de prospecção diferentes, pode facilmente acontecer que um contato esteja presente em vários arquivos. Neste caso, a deduplicação de dados permite evitar o contato com o mesmo prospecto várias vezes.
Entretanto, esta distinção não deve ser absolutizada. O que a duplicação e a deduplicação têm em comum é que resultam na presença de dois contatos/dados idênticos no sistema de informação. Em um SI unificado com RCU, as operações de deduplicação e desduplicação são bastante similares.
Quais são as abordagens tradicionais da deduplicação?
A criação de dados duplicados está freqüentemente ligada a diferenças sintáticas resultantes de erros de entrada por parte do pessoal de vendas ou consultores de clientes, inversões, uso de abreviaturas (para endereços postais, por exemplo), etc. Os dados inseridos no formulário de contato, no formulário de criação de conta ou durante uma troca com o serviço de atendimento ao cliente não são estritamente idênticos, o que leva à duplicação de dados no sistema, no CRM, por exemplo.
Os dados são uma coisa viva, a maior parte deles está fadada a mudar com o tempo: o indivíduo se muda, muda de número de telefone, muda de sobrenome (casamento, divórcio…), etc. Isto também pode contribuir para criar duplicatas. Isto também pode contribuir para a criação de duplicatas. Neste caso, a empresa deve estabelecer regras de prioridade entre as fontes de dados para identificar os dados “bons”, aquele que é mais provável que seja verdadeiro > e, portanto, aquele a ser utilizado.
Descubra 10 dicas para a construção de Páginas de Aterragem otimizadas para coleta de chumbo.
Os usuários do sistema de informação geralmente são capazes de identificar rapidamente as informações associadas a um indivíduo, para identificar a identidade do contato por trás das diferenças sintáticas. Entretanto, uma vez atingido um determinado volume de dados, torna-se essencial usar mecanismos de automação para detectar e corrigir essas diferenças e remover dados duplicados. Aqui estão as principais etapas do processo:
Etapa 1: Gerenciamento de dados
- RNVP (Reestruturação, Normalização, Validação Postal) processamento de endereços postais
- Padronização dos números de telefone.
- Etc.
Segundo passo: A implementação de um algoritmo para calcular uma pontuação de proximidade, e isto para cada tipo de dado: nome, nome, endereço postal, e-mail, telefone… Dois métodos são possíveis:
- Uma análise de similaridade de fios e o uso de cálculos de distância: Levenstein, Hamming…
- Uma sólida análise de similaridade, que consiste em comparar o conteúdo dos dados de um ponto de vista fonético. Os métodos de metafone e metafone duplo são amplamente utilizados para este fim.
Terceiro passo: o cálculo de uma pontuação de similaridade global do banco de dados. É aqui que entra em jogo um modelo de aprendizagem de máquinas para construir um indicador de similaridade composto. Métodos do tipo floresta aleatória podem ser implementados de forma útil neste nível.
Que ferramenta você deve usar para dedicar seus dados de clientes?
Agora vamos lhe apresentar 3 ferramentas muito boas para dedicar seus dados de clientes.
Octolis
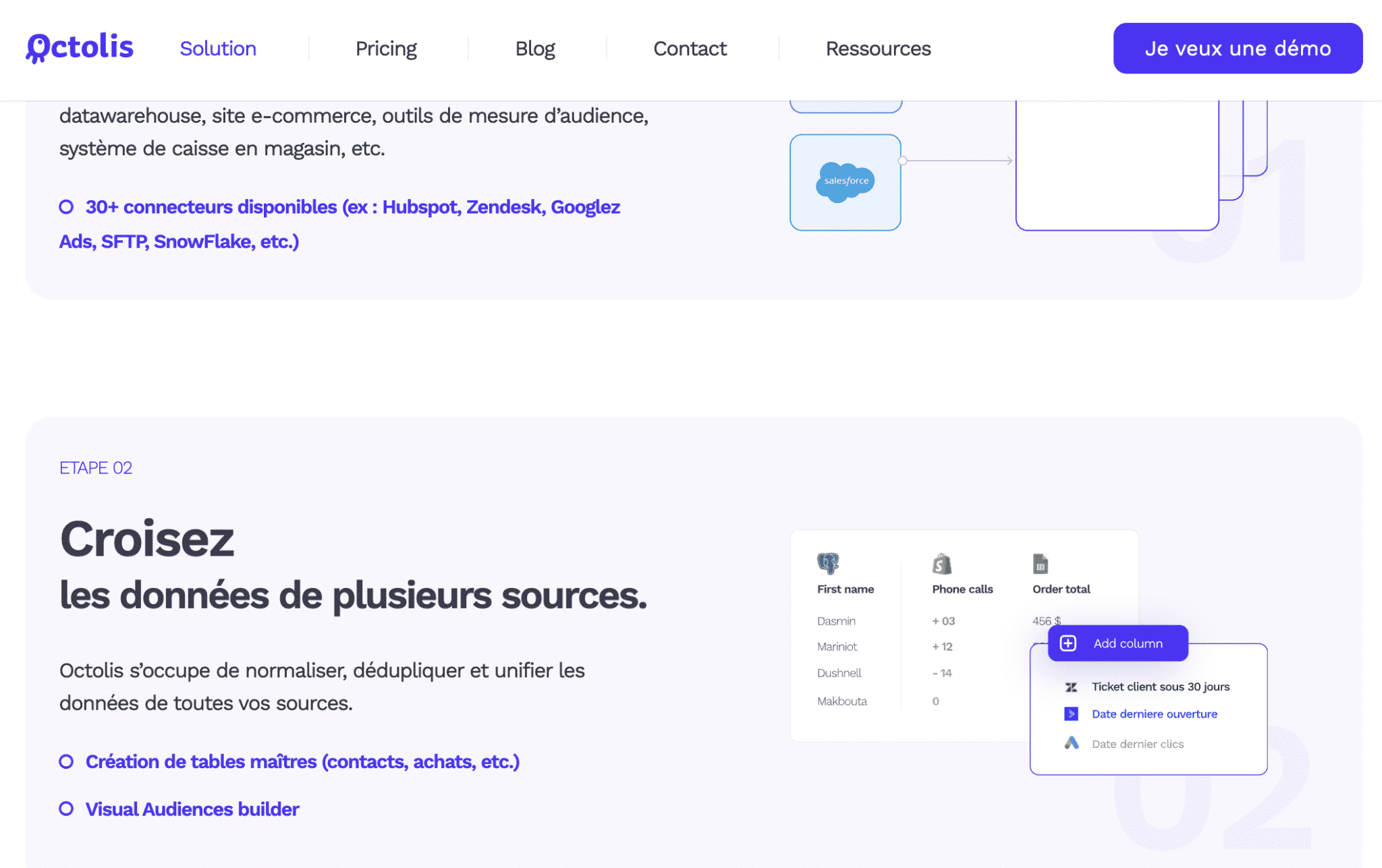
Octolis é uma Plataforma de Dados do Cliente (CDP) leve, projetada para conectar suas fontes de dados, limpá-las, desduplicá-las, unificá-las e enriquecê-las. A partir daí, a ferramenta oferece a possibilidade de criar audiências, pontuações, segmentos, agregados que você pode então sincronizar em poucos cliques em suas ferramentas de Vendas e Marketing para seus casos de ativação de uso.
Ao contrário dos CDPs tradicionais, a Octolis é independente de seu banco de dados de clientes (seu armazém de dados) e lhe dá controle total sobre seu banco de dados.
A ferramenta deduplica contatos e empresas usando várias chaves, por padrão: o usuárioId, ou Sobrenome x Nome x E-mail ou Sobrenome x Nome x Telefone. A equipe da Octolis pode, se necessário, criar novas chaves, mediante solicitação.
Software DQE
Fundada em 2008, a DQE Software é um provedor de soluções especializado no gerenciamento da qualidade de dados e na implementação de repositórios exclusivos de clientes. A DQE desenvolveu várias tecnologias inteligentes para otimizar a qualidade dos dados dos clientes, cobrindo toda a cadeia desde a coleta de dados até a ativação do marketing. As soluções DQE estão disponíveis em modo nuvem (SaaS) ou como versões hospedadas em servidores da empresa. Elas são projetadas para interagir facilmente com ferramentas CRM e ERP. Com mais de 150.000 usuários e uma taxa de crescimento anual de +20%, o Software DQE é uma referência no mercado.
Descubra nosso software Top B2B CRM & Marketing com versão gratuita.
Amabis

Com escritórios na França e no Marrocos, a Amabis é uma empresa francesa que atua no mercado de gerenciamento de dados de clientes há mais de 20 anos. A empresa tem quase 500 clientes. Historicamente, a Amabis era especializada no gerenciamento de CRM & bases de dados de marketing (AmaBase), o que lhe permitiu adquirir uma forte experiência no gerenciamento de dados de clientes e tornar-se um dos principais players no mundo da Gestão de Qualidade de Dados. A Amabis oferece uma nova solução de CRM desde 2015, AmaCRM, que integra nativamente a gestão da qualidade dos dados.
E se você aprendeu a se dedicar em SQL?
Você sabia que é possível deduplicar dados de clientes de seu banco de dados relacional usando uma consulta SQL “simples”? Tiramos algumas screenshots para explicar rapidamente a lógica. A consulta que vamos apresentar a você permite transformar uma tabela de contatos em um único repositório de clientes (UCR). Aqui está o resultado:
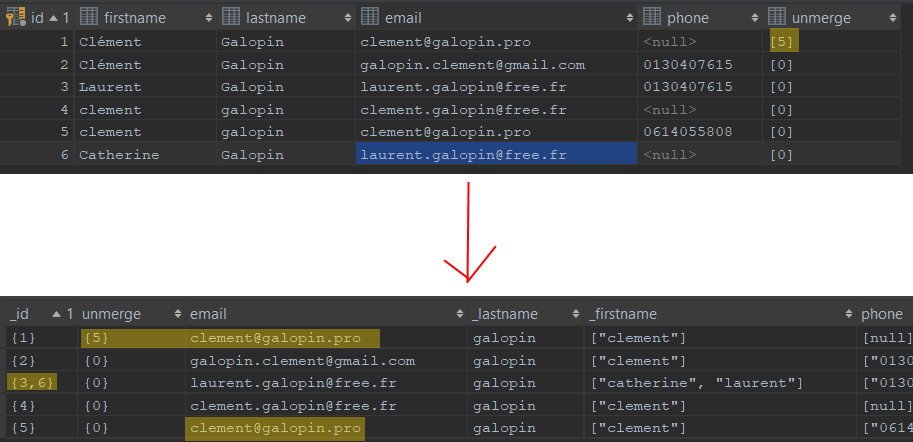
A primeira captura mostra a tabela antes da execução da consulta SQL, a segunda a tabela após a execução da consulta.
Esta consulta, como você pode ver, leva em conta regras não conflitantes, de modo que dois contatos erroneamente associados podem ser dissociados a posteriori. Isto é muito prático. Neste caso, ela impede que dois membros da mesma família sejam associados por causa da identidade do nome. Lembre-se de que a deduplicação é o processo que consiste na fusão de contatos idênticos em seus bancos de dados. Neste processo, um dos maiores riscos é a fusão de contatos que não são idênticos. As regras de não fusão atuam como salvaguardas. Se você decidir desduplicar seus contatos em SQL, recomendamos fortemente que você implemente estas regras.
Descubra nosso guia completo sobre a arte de identificar visitantes anônimos em um site B2B.
O outro interesse desta consulta SQL é que ela consiga fazer uma junção fuzzy no primeiro nome, assimilando os primeiros nomes acentuados / não acentuados e os primeiros nomes com / sem letras maiúsculas > Clément = clement. Lembre-se de que as diferenças ortográficas/sintáticas são a principal fonte de duplicatas. Aqui está a pergunta:
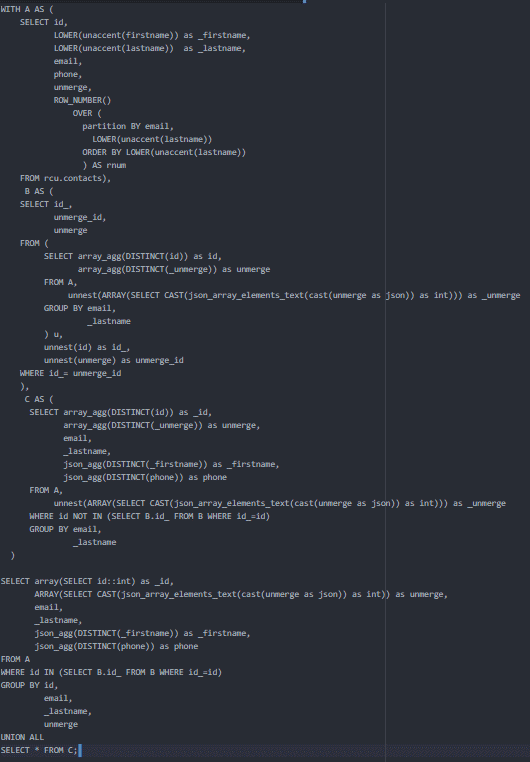
Tomamos o tempo necessário para detalhar cada uma das partes que ela contém, para ajudá-lo a entender melhor a lógica.
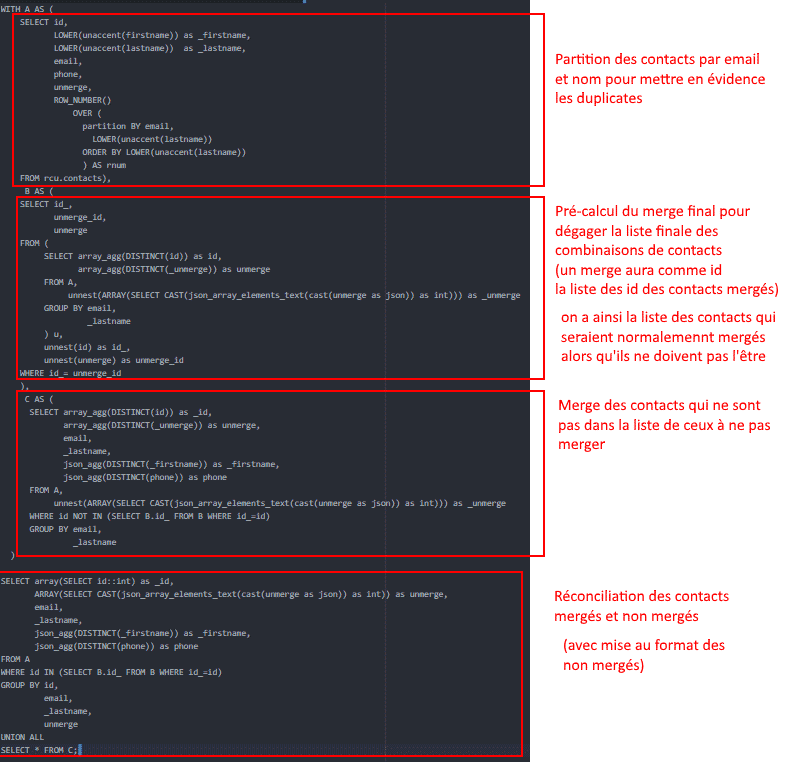
Se você está familiarizado com SQL e gerenciamento de banco de dados relacional, você pode deduplicar seus dados de clientes em SQL. Isto é o que queríamos mostrar neste pequeno exemplo.