
Le web scraping consiste à extraire automatiquement les données affichées sur un site web. Jusque là tout le monde est à peu près d’accord.
Mais concrètement, comment ça marche? À quoi ça sert? Et pourquoi est-ce qu’on en entend de plus en plus parler dans des contextes business?
Ces données sur vos clients, prospects et concurrents permettent de:
- Constituer une liste d’entreprises ultra-ciblée ;
- Identifier les profils qui vous intéressent au sein de vos comptes clés dans une logique d’ABM;
- Hiérarchiser vos opportunités au sein de votre CRM (lead scoring, etc.);
- Détecter automatiquement des signaux chez vos prospects pour passer à l’action au bon moment. Ça s’appelle l’EBM: Event Based Marketing.
Pour faire honneur au sujet qui nous semble être un des aspects essentiels de la “digitalisation” de la fonction commerciale, on a discuté avec nos copains de chez Captain Data. Des experts absolus sur le sujet, au contact des équipes commerciales les plus avancées depuis des années. La pointe de la pointe.
Dans cet article, tout ce qu’il faut savoir des applications commerciales du web-scraping pour devenir incollable sur le sujet 👇
Sommaire
Le web scraping, c’est quoi ?
Avant toute chose, posons les bases de cet article avec une définition du web scraping.
Le web scraping : définition
Concrètement, le web scraping (“racler le web” en anglais) est le processus d’extraction de données sur un site Web.
Il permet de récolter une multitude d’informations précieuses, comme une adresse e-mail, un numéro, une adresse etc. et de les rassembler dans une base de données.
On distingue deux manières de faire du scraping : manuellement ou automatiquement.
- Le scraping manuel consiste à copier-coller des informations/données dans le but de se constituer une base de données. C’est un travail très chronophage qui est généralement utilisé pour de petites quantités de données.
- Le scraping automatique: il y a tout un tas d’outils de scraping qui permettent d’explorer et d’extraire des informations depuis des sites web.
Aller plus loin
Le truc fondamental à comprendre quand on parle de scraping, c’est qu’on ne fait que récupérer de la donnée qui est mise à disposition de façon déjà hyper structurée sur des sites web. Google et tous les autres moteurs de recherche le font aussi. Et si vous avez un site web, vous faites tout pour que Google puisse vous “scraper” super facilement pour qu’il vous indexe.
Des méthodes de plus en plus démocratisées
Depuis quelques années, les SDRs se “réapproprient” l’intégralité du funnel de vente. On le voit de plus en plus sur la génération de contenu, mais aussi sur la génération de leads pure, notamment avec des méthodes comme le scraping. Chris Gerretsen en parle assez bien dans son bouquin de “The augmented salesperson : B2B Sales in the digital age“.
Le recours croissant à l’automatisation et au besoin de données au sein des entreprises a accéléré la popularité du scraping. Pour une équipe commerciale, le scraping permet de:
- Automatiser le processus de collecte de données à grande échelle,
- Débloquer des sources de données apportant une valeur ajoutée à l’entreprise,
- Prendre des décisions éclairées, basées sur les données.
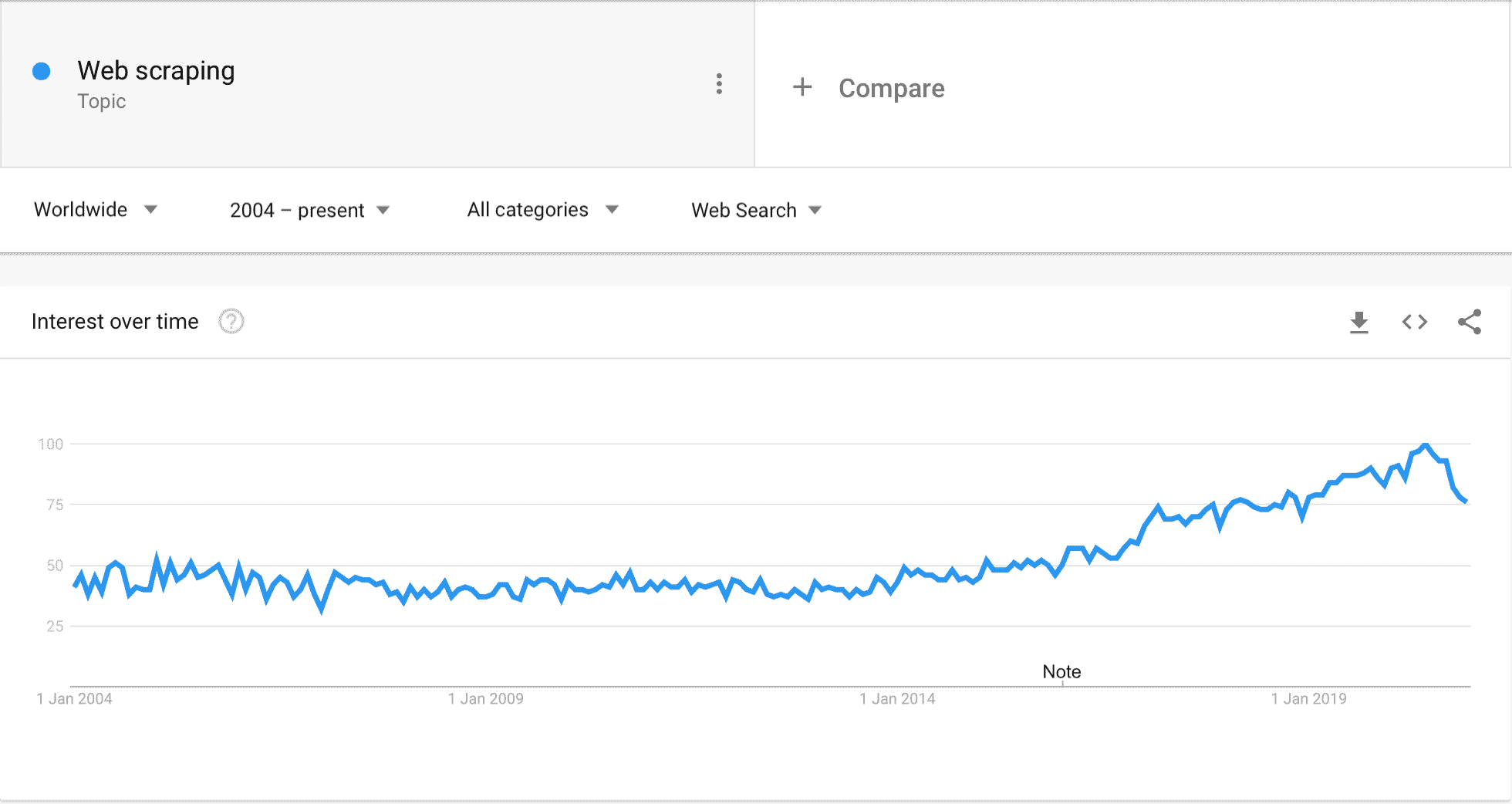
Parallèlement, des outils comme Captain Data se sont développés pour démocratiser ces méthodes qui étaient traditionnellement réservées à des développeurs confirmés. Aujourd’hui, ce genre d’outil permet de se concentrer sur la réflexion business, le choix des sites & des informations à obtenir, et récupérer sans aucune connaissance technique des profils linkedin, des résultats sur leboncoin ou pages jaunes, ou des listes d’entreprises & contacts sur google maps.
Aller plus loin
Même les investisseurs en capital-risque (venture capitalists) utilisent de plus en plus le scraping pour identifier les entreprises en création et à fort potentiel. Cela montre assez bien comme le sujet se démocratise rapidement, et va bien au delà de quelques obscurs growth hackers / gourous.
#1 Utiliser le webscraping pour constituer une liste d’entreprises cibles
Pour vous constituer un fichier de prospection, la première étape est vraiment de créer un Ideal Customer Profile (Profil de Client Idéal) actionnable : c’est le plus important et le plus compliqué dans la mesure où cela permet d’identifier quelle source de données choisir en fonction de vos cibles et de leur présence digitale.
Adresses, numéros de téléphone, e-mails, effectifs etc. avec un peu de recherche, on peut scraper presque toutes les informations possibles et imaginables sur une entreprise cible, depuis son site web. L’idée est donc d’identifier les sources de données qui nous permettront de remonter jusqu’au site web.
Avant de débuter, la première étape consiste à trouver ou à se constituer une liste d’entreprises. Pour ce faire, utilisez des ressources spécialisées comme :
- Linkedin Sales Navigator, du pain béni si votre cible y est active. Grâce à la puissance des filtres de Sales Navigator, vous obtenez des listes d’entreprises relativement petites mais qui extrêmement bien ciblées.
- Google Maps, une source en or pour les marchés peu digitalisés. Vous êtes à la recherche de profils plus spécifiques et encore peu digitalisés (commerçants, artisans etc.) ? Google Maps est très efficace pour trouver des numéros de téléphone et des sites web de ce type de profil.
- Les Pages Jaunes, la référence pour trouver les noms commerciaux, numéro de téléphone, adresse et site web. Filtrez par secteur d’activité et localisation et constituez-vous rapidement une liste d’entreprises cibles.
- Le Système National d’Identification et du Répertoire des Entreprises et de leurs Etablissements (SIRENE), le fichier des entreprises françaises accessible librement et gratuitement. Même si les données ne sont pas facilement exploitables, il permet une identification à grande échelle des sociétés se créant sur le sol français. Vous obtiendrez alors deux points de données importants : la raison sociale de l’entreprise et l’adresse.
- Les annuaires spécialisés dans le secteur du bâtiment par exemple, ou des startups françaises. Les annuaires spécialisés ne sont pas à sous estimer car ils permettent, souvent, de trouver plusieurs centaines d’adresses d’une cible très précise. Même si cela dépend, évidemment de la qualité des données disponibles, scraper ce type d’annuaire est assez facile et peu coûteux.
#2 Identifier les bons contacts dans chaque compte cible
Plusieurs options sont disponibles pour identifier les bons contacts dans chaque compte. Premièrement, il est possible d’enrichir ses données B2B grâce à Linkedin. Visitez les profils qui vous intéressent et utilisez un outil externe pour gagner du temps.
En utilisant les meilleures solutions d’enrichissement de données, en B2B comme societeinfo ou dropcontact, les données sont enrichies automatiquement.
D’autres outils, comme Captain Data, sont utiles pour piloter le compte Linkedin d’autres personnes et récupérer des données à la source. Par exemple, une personne de l’équipe marketing peut gérer plus de 20 comptes Linkedin en parallèle pour générer un maximum de leads.
Deuxième option, effectuer du cross-canal entre l’envoi d’e-mail et de séquences de messages sur Linkedin sur des audiences très ciblées. Des outils comme Waalaxy permettent d’automatiser tous le processus.
Aller plus loin
Une campagne sur 200 leads hyperpersonnalisés vaut toujours mieux qu’une campagne de masse sur des milliers de leads non qualifiés. Le scraping n’a pas nécessairement vocation à permettre de traiter plus de volume. Automatiser, c’est gagner en qualité (moins d’erreurs), et ça permet aussi de travailler en flux, avec des données ultra récentes, plutôt que sur un fichier de 10 000 lignes qui vieillit à mesure qu’on le travaille…
#3 Détecter des signaux faibles
L’Event-based marketing est une technique marketing où les internautes reçoivent des communications personnalisées en fonction de leurs actions/comportement. Il repose sur la mesure des interactions entre l’internaute et le site web d’une entreprise.
Ici, le mot-clé est “event” : un évènement est l’enregistrement d’un comportement sur un site web. Il est lié à l’identité de l’utilisateur et des attributs peuvent y être stockés.
L’Event-based marketing permet d’améliorer considérablement la capacité, la rapidité et la qualité du marketing. Grâce à la technologie, de nouveaux outils et techniques apparaissent, conçus spécifiquement pour l’EBM.
Le scraping permet de surveiller et de détecter les signaux liés à l’activité d’un prospect/concurrent afin de détecter des opportunités business en fonction de différents signaux.
Voici quelques astuces pour identifier les entreprises en fonction de vos besoins :
- Si vous avez la volonté d’identifier les entreprises en croissance, utilisez les filtres spécifiques correspondant, par exemple, la croissance du nombre d’employés sur Sales Navigator.
- Si vous souhaitez identifier les entreprises qui recrutent pour un poste spécifique, utilisez, par exemple, la section “job search” sur Indeed et enrichissez les données déjà récoltées. Allez également sur Linkedin pour identifier les entreprises qui recrutent via les offres d’emploi postées.
- Les avis négatifs sont d’excellentes sources pour “récupérer” les clients mécontents de votre concurrent. Un outil comme ReviewFlowz permet d’être notifié directement dans Slack lorsqu’un avis est publié sur le profil d’un ou plusieurs concurrents.
- Détectez les dernières levées de fonds pour améliorer le timing sur une vente (une entreprise qui lève beaucoup d’argent va très probablement recruter et équiper certains posts).
#4 Scorer son CRM
Le scraping peut également être utilisé pour qualifier son marché et identifier ses ICPs. Là encore, identifier le site web d’une entreprise a beaucoup de valeur car cela permet notamment :
- D’apporter beaucoup plus de contexte sur l’entreprise ciblée, grâce aux réseaux sociaux, aux données légales, à l’adresse, ou à des informations facilement identifiables: plusieurs langues disponibles, liens disponibles en navigation – pour identifier l’existence d’un blog par exemple – numéro de téléphone disponible ou non, etc.
- De créer des patterns pour trouver les e-mails des employés. Un pattern, c’est la structure d’une adresse e-mail. La plupart du temps, les adresses professionnelles sont construites comme ceci : [email protected]. En trouvant le pattern, vous pouvez trouver les adresses email de tous les employés d’une entreprise. Un outil pour trouver les bons prospects, comme Hunter, peut vous aider dans cette tâche.
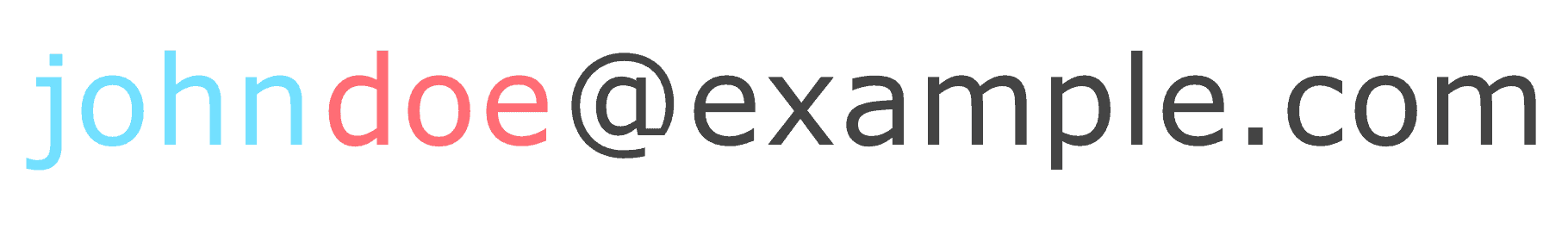
- D’identifier automatiquement le trafic sur un site ou même le secteur d’activité de l’entreprise (en scrapant les titres par exemple).
- En combinant votre outil de scraping avec une solution comme Builtwith ou Similartech, il est possible de trouver les outils utilisés par les entreprises et ainsi en déduire les opportunités business. Cela vous permet de scorer vos prospects pour évaluer le potentiel de chacun d’entre eux et ainsi mettre à jour votre logiciel CRM.
Le conseil de Salesdorado
La base Sirene en open data est également une excellente ressource pour trouver de nombreuses informations sur une entreprise (nombre d’employés, revenu etc.), autant d’éléments à exploiter pour hiérarchiser vos opportunités business. Vous pouvez utiliser leurs APIs directement, ou regarder du côté de societeinfo pour des services de Sirenisation & d’enrichissement automatique.
#5 Obtenir des données toujours à jour
Ici, parlons de la data quality. La data quality, c’est la capacité d’une entreprise à garder ses données à jour à travers le temps. Ces données sont alors utilisables pour des opérations marketing et commerciales.
La durée moyenne en poste d’un employé est de deux ans. Au bout d’un mois, un fichier composé de 1000 lignes aura donc plus de 5% de lignes obsolètes. Au bout de deux mois, ce chiffre montera à 10% et ainsi de suite.
L’obsolescence des données est super rapide. Pour garder vos données à jour, soit il faut traiter tout le marché en moins d’un mois, soit la base de données doit être mise à jour régulièrement.
Ici aussi, le scraping permet de lutter contre l’obsolescence des données.
- Grâce au scraping, on peut identifier un changement de CMO ou de CTO et anticiper le churn. Réciproquement, un changement de décideur entraîne souvent un changement d’outil, ce qui peut constituer une opportunité pour votre activité.
- En utilisant le scraping de façon régulière, on peut également obtenir des signaux réguliers sur le long terme (une levée de fonds par exemple) et donc identifier de nouvelles opportunités.
#6 Rendre la donnée opératoire
Nous l’avons expliqué juste avant, la data quality permet de garder à jour les données récoltées par les entreprises. Mais, une donnée n’est utile uniquement lorsqu’elle est disponible au sein des outils que vous utilisez au quotidien et lorsqu’elle est identique dans tous ces systèmes: logiciel CRM, logiciel de marketing automation, back-office opérationnel, outils de reporting, de comptabilité, etc. etc.
Pour qu’elle soit exploitable, la donnée doit être accessible et actionnable, et pas uniquement disponible dans des outils de reporting qui permettent d’adapter votre stratégie après coup.
On est pas hyper objectifs, mais Captain Data est à notre avis une des solutions qui appréhende le mieux ces problématiques. En effet, ils ne s’arrêtent pas au seul logiciel CRM, et vont jusqu’à la dissémination de la donnée dans tout l’écosystème “data” de l’entreprise. Une démarche qui est à notre avis indispensable aujourd’hui.
Le conseil de Salesdorado
Attention : le tout n’est pas de récupérer autant de données qu’on peut (même si c’est assez grisant). L’important est de rendre les données accessibles. C’est d’ailleurs la mission de Captain Data : rendre les données B2B accessibles et actionnables.
Les avantages du webscraping en résumé
De nombreuses raisons poussent les commerciaux B2B à utiliser des solutions de web scraping :
- L’automatisation : copier-coller des grandes quantités de données est un travail fastidieux. Heureusement, les outils de web scraping rendent aujourd’hui l’extraction de grand volume de données à la fois simple et rapide.
- La rentabilité : extraire des données manuellement est une tâche longue et coûteuse. Le web scraping a résolu ce problème en récoltant de grandes quantités de données avec un minimum d’effort.
- Mise en place simple : Des outils comme CaptainData ont démocratisé l’accès à beaucoup de sources de données très précieuses comme Linkedin, Google Maps, les pages jaunes, etc.
- Maintenance réduite : le coût de la maintenance est un élément souvent ignoré lors de l’installation de nouveaux outils. Heureusement, les technologies de web scraping nécessitent peu ou pas de maintenance au fil du temps.
- La vitesse : la rapidité avec laquelle les outils de web scraping réalisent les actions voulues est un autre avantage.
- Précision des données : les outils de web scraping ne sont pas seulement rapides, ils sont aussi très précis. L’erreur humaine est souvent un facteur à prendre en compte lors de l’exécution manuelle d’une tâche. Par conséquent, l’extraction de données par un outil dédié est bien plus qualitative.
- Gestion efficace des données : Le web scraping permet de choisir les données que vous souhaitez collecter puis d’utiliser les bons outils pour le faire correctement. De plus, l’utilisation de logiciels et de programmes automatisés pour stocker les données garantit la sécurité de vos informations.
Quel outil de web scraping choisir ?
Plusieurs types d’outils existent pour effectuer du web scraping :
- Les outils open source, qui rendent le web scraping moins coûteux et facilitent son exécution. Les outils les plus utilisés sont Scrapy, Selenium, BeautifulSoup et Puppeteer.
- Les solutions propriétaires, segmentées en deux types : Les solutions avec interface de programmation où une clé API est fournie pour accéder aux données; et les solutions où aucune compétence en programmation n’est nécessaire et qui visent à démocratiser le scraping.
- Les solutions SaaS qui utilisent un ensemble diversifié d’adresses IP et de signatures numériques, agissant comme un groupe d’utilisateurs naviguant sur un site Web plutôt que comme un robot automatisé.
- Les services gérés, également appelés data-as-a-service (DaaS), sont plus faciles à utiliser pour les entreprises qui ont besoin de données à grande échelle. Yipitdata, PromptCloud et ScrapHero en sont des exemples concrets.
- Les solutions “maison”. Tant que l’entreprise dispose d’un personnel technique capable de s’acquitter de la tâche, et que le scraping est destiné à un projet stratégique, construire une solution maison est l’option la plus optimale.
Aller plus loin
Pour bien choisir votre outil avant de scraper un site, commencez par regarder si vous pouvez passer par Captain Data, c’est quand même beaucoup plus simple 😉 Pour des choses plus sur mesure, on vous recommande de parcourir notre article sur les outils de web-scraping. On a classé une dizaine de nos outils préférés par ordre de simplicité pour vous éviter de passer par des usines à gaz quand c’est possible.






